Experimenting with
embeddings for webpage recommendations has been in my backlog for a bit, it wasn't til I read
this post that I realized I could knock out a simple implementation in a weekend.
There are plenty of good resources on what embeddings are and how they work, I'll just skip to the parts that apply to my use case:
- Embeddings consist of text tokens paired with hundreds of floating point values. Specifically, "flower" -> [0.44, -0.07, 0.15, ...]
- The values are determined by training done on a big computer run by someone who does it as their day job. How they get there is complicated but the result is simple: 'car' and 'Fiat' have similar vectors, 'porcupine' and 'envy' have different vectors.
- From the post linked above, adding the vectors of multiple words (elementwise) produces an aggregate meaning, so you can compare "the quick brown fox jumps over the lazy dog" with "how vexingly quick daft zebras jump". Caveat: I don't know if addition is a best practice or just some blogger's simplified approach.
The subtasks to get to Hello Embeddings were not substantial:
- Get an embedding table.
- Encode webpages as an aggregate vector.
- Compute similarity using vector math.
My baseline implementation
I already have code to match/recommend webpages, an unsophisticated solution that does a set intersection of 1-grams, 2-grams, and 3-grams from each page. It's worked well so far but could stand to benefit from the fuzzy/semantic correlation provided by an ML approach. Most importantly, the code and data from the baseline matcher was quite helpful in getting past some challenges with doing embeddings on a humble gaming PC.
Downsizing
Lists of embeddings are not small:
vocabulary size * 100-500 floating point numbers. A minimum of two gigs is a lot to ask and searching for a bunch of arbitrary strings isn't the kind of thing you want to do on disk. Since I don't believe in databases, I decided to look at the data itself.
It didn't take long to see that
the list had clutter: stopwords, ambiguous acronyms, and numeric values. Borrowing the list of 1-gram stopwords from my naive implementation, I got the following:
2,684,369 stopwords
1,845,662 okay words
Cutting the list by more than half was a good start but 1.8M words is still a few hundred megs.
Perhaps the low-SNR terms not in my stopword list could be determined from their vector data?
I printed a few words and the max value from their corresponding vector, the idea being that a word with strong semantic meaning might have very high max value. Of course, a word's meaning could be split between multiple vector elements, but it's a start.
word max of absval
---- -------------
the -0.4605
of -0.4943
is 0.5202
by 0.5663
born 0.8322
category -1.4007
medalists -2.0290
Stopwords showed values close to 0, more meaningful words seemed to go strongly positive or negative. I compiled
a histogram of max values (absolute value, multiplied by 100 for readability):
Max Count
------- -----
[<= 19] : 2
[20:24] : 108
[25:29] : 4249
[30:34] : 31849
[35:39] : 95061
[40:44] : 161162
[45:49] : 193109
[50:54] : 191068
[55:59] : 170870
[60:64] : 148120
[65:69] : 128406
[70:74] : 111729
[75:79] : 99438
[80:84] : 89559
[85:89] : 79901
[90:94] : 69961
[95:99] : 58415
[100:104]: 46316
[105:109]: 34446
[110:114]: 24920
[115:119]: 16796
[120:124]: 11412
[125:129]: 7083
[130:134]: 4524
[135:139]: 2848
[140:144]: 1754
[145:149]: 1056
[150:154]: 702
[155:159]: 435
[160:164]: 269
[165:169]: 182
[170:174]: 122
[175:179]: 89
[180:184]: 64
[185:189]: 50
[>= 190 ]: 112
So if I wanted to get down to the n-thousand most meaningful(?) words,
perhaps I could just set a threshold using the histo counts. The code also spat out a histogram of median embedding values, perhaps a high median would indicate strong semantic meaning across multiple dimensions:
Median Count
------- -----
[0:2] : 0
[3:5] : 74
[6:8] : 108774
[9:11] : 514049
[12:14]: 443230
[15:17]: 297473
[18:20]: 220397
[21:23]: 142686
[24:26]: 48517
[27:29]: 8585
[30:32]: 1688
[33:35]: 425
[36:38]: 164
[39:41]: 79
[42:44]: 29
[45:47]: 12
[48:50]: 1
[51:53]: 2
[54:56]: 0
Using max >= 1.2 (120 as listed in the histo) and median >= 0.24 (24) I created
a pruned list of embeddings. The results looked like this:
internationalis
insat
inmortales
imathia
osteotomy
ousia
unomig
urayasu
zien
yakan
xylophanes
46kbb
satánico
sénégalaise
moerdijk
While these words no doubt
have ample meaning, they might not come up so frequently in blog posts and other
Outer Web pages.
Existing work came to my rescue once again. I had
a trigram whitelist (the opposite of stopwords) as well as an index of terms used for search. The search terms are constructed by iterating over every indexed Outer Web page and tossing out ones that appear too frequently or too infrequently.
Filtering the embeddings using these lists gave me 41,000 words and a totally reasonable 30mb memory footprint. But is a 41k vocabulary enough to characterize the meaning of an arbitrary webpage? The answer is nuanced, but it starts with taking a look a some random pages and seeing what words hit:
|
https://ahistoryofjapan.com/2024/11/11/the-meiji-reformation/
|
|
edwards christianity temple shogunate japan damaged reformation bronze lynne temples sentiment illustration smashed buddhist burning season
|
|
https://moitereisbuntewelt.blogspot.com/2020/01/british-paratroopers-colour-guide.html
|
|
welt sicily sport sand wehrmacht uniform models soldier russian paint wooden airborne trousers unit soviet kitchen goodness scrim translate strokes 28mm moons cloth documented replacement saddle disruptive figures british painting roman shading window irony pale paratroopers lighter fractions patterns guides cheers maroon wwii military germans superb legion gaiters darker scarlet gaming recesses cavalry obscure faded pulp tutorial bunte brackets ferrari famous vallejo wargamer glazes paints darkest italy transitions scifi rifle patches dried tricky earth beige overlap elaborate
|
|
http://alifeinphotography.blogspot.com/2022/08/a-peterbilt-prototype-in-infrared.html
|
|
crosses america display jenkins minolta byways stashed highway corporations truck infrared prototype parked photographing barns glory keeper organizations spanning scanner travel canon photographed gloria camera countries film records assignments philosophy antique photography agencies nature career amazon 1920s historian mission humanitarian
|
|
https://vickiboykis.com/2018/02/19/building-a-twitter-art-bot-with-python-aws-and-socialist-realism-art/
|
|
concrete firing library polling models workflow shoulder credentials uploading cloud wikiart amazon news software vicki profiles console painting script maintenance leads tweets captions scrape metadata forms records functions partisan extract cabin stalin json systemic followers imports string sleeping handler supportive distribution code overload directory realistic stream interval genre programming environment twitter tweaking acces processs prototype lambdas python technology libraries locally surrounded realism aims kinesis instructions developer developed arguing downloading noisy decode socialist artwork posting websites development triggered russian genres classifier functionality soviet kitchen filename docs animal headlines hashtag repeats emotion education artist scenes painter analytical tears artists classical scraping party travis toxic scraper javascript bird paintings uploaded documentation propaganda nudity refactor regime scroll communism dictionary clears client immobilized government machines science engineer array waterfall artworks testing experimenting dependent linux database asleep boundaries component pencils feasible revolution scripts architecture execution operations dictionaries humanity hooks trial
|
Comparison
With a slimmed-down list of embeddings loaded into memory, I could
iterate over every page and produce a single embedding vector by summing the component words. Comparing two pages could be accomplished by computing the cosine similarity of their embedding vectors.
Heuristic search
Cosine similarity comparison is reasonable for comparing two webpages or even for finding related posts within my blog (n = 700ish). It's not reasonable for
"here's an arbitrary webpage, find me similar ones in the hundreds of thousands of Outer Web pages". But neither was trigram comparison, and that's why
Outer Web search is a two step process:
- Query a keyword index for posts with matching terms.
- Starting with the pages found in 1, search the connected graph of pages until a 'done' condition is met.
To reiterate, cosine similarity is an easy win for making Step 2 better, can it do anything for Step 1? Perhaps.
One-hot index
I created a list of posts that have the highest similarity to each of the possible
one-hot vectors. For instance, a vector [0.0 0.0 0.0 1.0 0.0 ... 0.0] is most similar to the following posts:
- Laura Kalbag - The Destiny Machine
- Imposter Syndrome, Dunning-Kruger, or Just Do It · For my friendgineers
- Ghostbusters: Frozen Empire - Jason Gaston
- Blog | Thevioletwest
- Cinderella Moments: Peony Manor Custom 1/12 Scale Dollhouse
Now, I have no idea why those posts are semantically similar and neither does the embedding data. It is, after all,
an entire internet of words distilled into a hundred categories. Some of the other indexes yielded results that look more alike at a glance.
- The Arcade / Blog
- How to Become Better at the Keyboard - Sebastian Daschner
- java.io.UnsupportedEncodingException problem & solution - Avi Zurel - @KensoDev
- Physical Memory Attributes (PMAs) · Daniel Mangum
- 16BPP.net: Blog / Added a Contact, Page
One more:
- Photography in zero visibility at the Sonoma Coast - aows
- Trip to Goa | Deepak's Views
- Small and Sunny - Learning to Surf
- Once this month - Learning to Surf
- Fjodin's 15mm World: Armies Army - VDV vehicles Pre release Sale now on!
With a little instrumentation, I could determine if one-hot graph entry points result in good matches relative to a basic keyword index.
Cosine similarity maths
Cosine similarity's Hello World is something like "King - Man = Queen". That is,
if you subtract the vector for 'man' from the vector for 'king' you get 'queen'. I did vector addition and subtraction on some randomly-selected terms to see what would happen. Randomly plucking words from the index gave me a lot of meaningless results, like 'taco' + 'dignity' = a variety of words resembling each.
Another way to illustrate it, here's an addition that makes sense:
blogosphere + recap
1. 0.750: tweets
2. 0.738: bloggers
3. 0.729: newsblog
4. 0.728: podcast
5. 0.727: lamestream
6. 0.725: podcasts
7. 0.723: scobleizer
But the subtraction goes off the rails a bit:
blogosphere - recap
1. 0.509: nationalism
2. 0.461: separatism
3. 0.458: feminists
4. 0.448: nationalist
5. 0.438: globalization
6. 0.438: activists
7. 0.437: nationalists
Another illustrative result:
embeddings are trained on the various possible meanings of a word, e.g. 'chihuahua' is both a dog and a state:
chihuahua + bear
1. 0.762: coyote
2. 0.724: sonora
3. 0.701: durango
4. 0.680: bobcat
5. 0.676: wolf
6. 0.674: sinaloa
7. 0.667: juarez
'Bear' has a variety of meanings but they appear to be dominated by the animal - at least when added to a chihuahua.
The
random keyword selection was pretty funny at times, e.g. vacation - dystopia:
vacation - dystopia
1. 0.439: homestays
2. 0.405: picnics
3. 0.395: resort
4. 0.390: resorts
5. 0.378: meals
6. 0.371: honeymoons
7. 0.370: cookouts
And though the similarity values are pretty low, I will personally confirm that cookouts and honeymoons are a lot like vacations without the dystopic elements. Speaking of dystopias:
tiktok + america
1. 0.664: effed
2. 0.649: firetv
3. 0.646: globl
4. 0.642: asshat
5. 0.638: jnpr
6. 0.632: bridgerton
7. 0.628: bedazzle
A few others:
- zoolander + honeymoon = shrek
- idiocracy - movie = misanthropy
- rants + censorship = deadnaming
- atlanta + waves = seattle
- atlanta - waves = gwinett
- motorsport - klm = supercars
Next month's follow-up post about being more efficient with this implementation:
|
|
2025.06.14
Compressed embeddings
Adding effiency to a simple embeddings implementation for webpage linking.
|
Moment of zen
 Embedding math
Embedding math |
tiktok + america = effed
|
Some posts from this site with similar content.
(and some select mainstream web). I haven't personally looked at them or checked them for quality, decency, or sanity. None of these links are promoted, sponsored, or affiliated with this site. For more information, see
.


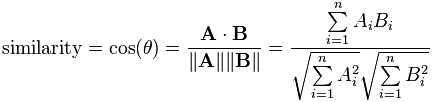



![[+]](https://www.chrisritchie.org/kilroy/archive/2025/03/trolley_fixed.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2015/07/warrior.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2025/03/elden_ring_placidusax_felled.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2019/01/viscera_cleanup_mop.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2025/03/stove_hood.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2020/09/da_bears.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2025/03/elden_ring_glitch.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2015/02/far_cry_view_00.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2025/03/elden_ring_deathbird.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2017/05/dying_light_stadium.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2025/03/elden_ring_nights_cav.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2016/04/division_helo_00.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2025/04/medicine.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2015/11/deezer.jpg){kind=link}