|
|
Source. I've been using galaxy maps as proxies for the internet, Rob's forthcoming guest post will explain why. |
A few months back I @ed the void with
this request for
the ability to interconnect my site with similar, noncommercial content. It was an iteration on the 'Related' section of many websites and the oldweb concepts of links pages and blogrolls. With
Twitter and
Reddit imploding and
Google being beaten by
SEO and
AI, it seemed
we needed a better means for authentic information discovery on the internet.
Well I did (a quick and dirty prototype of) it,
I fixed the internet (for my own site).
This post is mostly about the design and coding experience. If that's too dry, here are
a couple of examples of posts with relevant external links found by the crawler/recommender:
- There are a couple of posts covering alternate views of the 2003 Cedar Fire.
- My Shasta photo log links to a pair of similar experiences and a post about Kyrgyzstan since, I guess, I haven't yet discovered many casual mountaineering blogs.
- My ER-all-nighter doomscroll session during the Wagnerkrieg has some neat articles about Pringles and Russian armor woes.
Note that each of these will likely be replaced with other - presumably better - links in the future.
Seed pages and crawl queue
The internet is a pretty big place and I'm looking to connect a thin sliver of it, so having a well-managed crawl queue seemed important.
I started with RSS/Atom/Feed files - xml published by bloggers providing an inventory of their writing. This gave me a starting point of (mostly) personal web links from people looking for visibility. XML feed are, by design, easy to parse - particularly when you only care about title, description, and url. There were some adversarial feeds where, for instance Wordpress put span tags around every word. Most of this is documented
in this post.
My harsh generalization about lists of rss feeds is that
they're all written by web coders publishing recipes as a resume builder. Javascript-enjoyers and blogs go together like moths and flame or bacon and chili powder. So most of my early results were repetitive, dry, and not (what would consider) interesting subjects like wheelies and 0DTEs and object oriented code. XML feeds are considerably more pure than wild hrefs but
I quickly decided to add discovered links to my queue. My hope was that all these web coding Melvins would link to Chad friends with more content variety like fantasy football and scuba and board games. Inevitably they'd also link to Git repos and documentation pages and Stack Overflow, so these efforts to improve variety would present an snr issue. But that would be a problem I could defer until I wrote the crawler.
The crawler
The post crawler was fairly straightforward and in my wheelhouse from a previous life:
pop a url from the queue, check its robots, read the fields of interest, ensure I didn't hit the same page twice (unless re-crawl == 1). But what were the "fields of interest"? This depended on my approach for measuring similarity/producing recommendations. So we'll have to do a little (ugh, process)
preliminary design.
Similarity measurement baseline
My
internal recommendation engine ("see other posts from my site") uses this:
intersection(trigrams_a, trigrams_b)
------------------------------------------ (divided by)
(size(trigrams_a) + size(trigrams_b)) / 2
It's quick, it's straightforward, it measures terminology overlap and normalized to devalue lengthy posts. It works well for the controlled environment of my own site. But
the greater internet has all sorts of adversarial cases, purposeful and otherwise.
Going with what you know
Rob wrote some early prototypes using scikit-ish Github projects. More recently he looked at BERT and other awesome vectorization/transformation approaches. I'll defer to his eventual guestpost on the matter but, suffice it to say,
I went with a very modest recommendation engine for my first iteration. I did add
a single layer of complexity to my tried-and-true trigram implementation: emphasis words. These could be pulled from descriptions, keywords, and headers to accomplish what
tags do, but in a more generic (but less precise) way.
Preliminary design complete:
my crawler just needs trigrams from the post's plaintext and emphasis items.
Post ingestor
Storing the post trigrams would paint me into a bit of a corner: if I wanted to come back to do tetragrams or locality sensitive hashing I'd have to re-scrape the page. So I decided to
store the post text itself and a list of emphasis terms. I could create an auxilliary trigram file and/or recreate the trigrams during comparison. But since I didn't need any html stuff, I could just have JSoup spit out the post text and slim the stored pages down considerably. More importantly, I couldn't see a scenario where I'd
want the markup except the for the probably-intractable objective of sorting the good text (post contents) from the bad (navigation, header/footer).
Since the (current) end goal of the recommender is a link preview, my ingestor also need to
parse the title, description, preview image, and canonical url from the html.
Scaling
Does this scale? The internet is big, even the non-commercial fringe is a lot to crawl and store. What's more, producing recommendations (at this stage) requires iterating over every indexed page for comparison. So while I was aiming for a minimum viable product,
I didn't want to blow up my hard drive or make a recommendation run take a long time.
So 10,000 files is a modest 100MB. That's easy to store and reasonably quick to iterate over. If this little experiment ever graduates to something more substantive, the only scaling issue is the O(N) recommendation process.
Recommender implementation v1.0
With the queue, crawler, and ingestor in place, it was time to flesh out the recommender/similarity measurement.
Trigrams and stopgrams
Since trigrams worked well for internal recommendations, I used them here. Digrams aren't enough, tetragrams are way too much. Probably. I discussed n-grams in
this post but the tldr is that n-grams are a set of each word, word pair, word triplet, and so forth. E.g. "quick brown fox" -> ["quick", "brown", "fox", "quick brown", "brown fox", "quick brown fox"]. And they're important in this application: "language" is fairly unspecific but "programming language" or "romantic language" or "gen-z language" carries a lot more meaning. I also found that proper nouns are extremely useful for associating web pages and typically require at least a digram: "Taylor Swift", "Supreme Court", "X formerly known as Twitter".
Here's an example dump of trigram intersection between a recent post and a fairly similar page from the webby web:
the site | deploy | site and | don't get | working | css | javascript |
generators | markdown | tedious | placing | compile | tech | for all |
concept | manage | the internet | tips | twitter | especially when |
comments | clean | dev | transition | static | markdown and |
static site | articles | run the | templates | websites | host |
stay | wordpress | internet | enjoy | writing | html | insights |
website | generated | them with | number | similar | city | make the |
the author | you should | features | site generators | talking about |
web | generator | user | search | seo | language | where static |
using this | publish | posts | static site generators | code | chance |
ssg | reddit | the wordpress | life | cases | templating | minimum |
create | files | netlify
This was some early data, the trigrams contain obvious stopgrams (stopword: a common word with little standalone meaning) like "don't get", "clean", and "number". These words could equally appear in a board game review or a post about a trip to Oregon. "Static site generator", "use case", and "css", on the other hand, strongly suggest the content of the text. Others, like "the wordpress" and "markdown and" don't gain much from the digram but serve to double the weight of the key word (for better or worse).
The usefulness of these tokens gets a little dicier with terms like "templating" and "static". They exist in non-programming contexts but aren't especially common. There's probably some neat Bayesian approach to be tried here (@backlog).
Stopgram efficacy
I quickly learned that
stopwords/stopgrams are very important in this approach. If Post A and Post B both talk about "Jerome Powell" and "quantitative tightening", it's very destructive to have that match be drowned out because Post A and Post C both contain the phrases, "you know what", "amirite guys", and "bananas". So my stopgram set grew with every comparison run and currently weighs in at 4,500 terms.
Despite all of this language-adjacent coding, I didn't sign up to ponder the intricacies of the English language and yet I found some things to noodle upon. In this case: that you can't just tensify every verb and plural every noun and verb every noun, every stopgram demands consideration. "World" doesn't say much about a particular post but "worlds" is a strong push in the direction of fiction/fantasy/sci-fi. Using "staggering" as a superlative isn't uncommon but if something is going to "stagger" it either took a punch to the gut or is a noncontiguous arrangement of things.
"Security" can be used in many contexts but it's rare to see "securities" used outside a discussion of investments/finance.
Math
The similarity measurement is accomplished as follows:
- Generate trigrams.
- Remove stopgrams.
- Intersect the trigrams of Post A and Post B.
This can be applied to post text and emphasis tokens and yield both a nominal intersection and a normalized one. I put these values get put in a datatype I call MultiscoreList that
takes an arbitrary number of score values and ranks the added items normalized for each column's min and max.
Iterating over the crawled web pages would look something like this:
-- Relative-- -- Nominal -- -- Keyword nominal -- -- Link --
Rel: 0.019969 nom: 26.0 keyw: 13.0 https://...
Rel: 0.014937 nom: 19.0 keyw: 9.5 https://...
Rel: 0.015353 nom: 19.0 keyw: 9.5 https://...
Rel: 0.043935 nom: 69.0 keyw: 34.5 https:/...
Rel: 0.025517 nom: 37.0 keyw: 18.5 https://...
Rel: 0.027312 nom: 44.0 keyw: 22.0 https://...
Rel: 0.029347 nom: 40.0 keyw: 20.0 https://...
Rel: 0.056619 nom: 173.0 keyw: 86.5 https://...
The final ranking would sort by an average of each column's nomalized value.
URL filtering
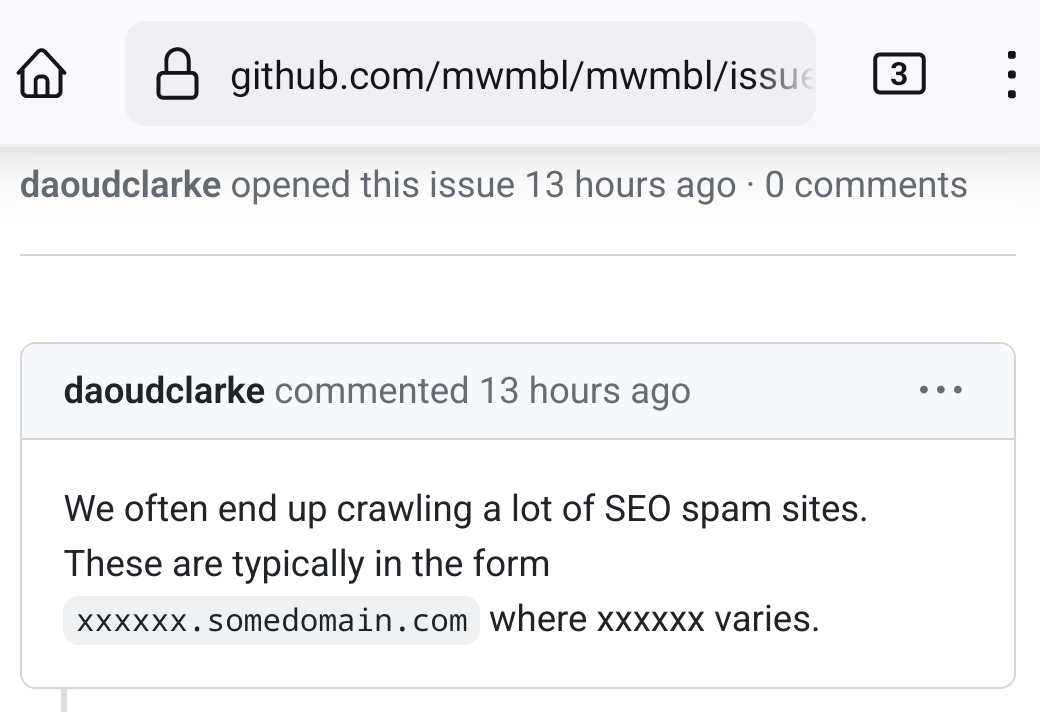
I quickly learned that the
most important component of this project is the url filter.
- The code's objective is to link the indieweb/smallweb/old web, not product pages, AI-generated garbage, or Web2 links that immediately hit a login wall. Filtering those parts of the internet before sending an http GET is the first line of defense against the normieweb.
- Web crawling is a limited resource, so it is beneficial to avoid any unnecessary crawls by divining meaning from the url.
- Storage is a limited resource, so avoiding gathering unnecessary post data is beneficial.
- The recommendation engine (in its current form) traverses every stored page, minimizing unnecessary post data is beneficial.
Domain blacklisting
There are some good domain blacklists out there. Marginalia has one. They can be tossed into a (large) set for a quick lookup. This list grew steadily as I crawled and examined the results.
Top-level domain blacklisting
|
|
From some crawler Rob linked me to. |
Top-level domains are a different story. I'd like to block *.affiliate-recommender.xyz but don't want to do the legwork of finding shop.affiliate-recommender.xyz, store.affiliate-recommender.xyz, uk-store.affiliate-recommender.xyz, etc. Now, it's trivial to do this using domain.endsWith(tld) or a regex, but
the O(1) domain blacklist check suddenly becomes O(n) as I'm checking each TLD blacklist entry against my url. Could I parse the TLD from an arbitrary url and check that against a TLD blacklist?
 Alex Martelli
Alex Martelli |
No, there is no "intrinsic" way of knowing that (e.g.) zap.co.it is a subdomain (because Italy's registrar DOES sell domains such as co.it) while zap.co.uk isn't (because the UK's registrar DOESN'T sell domains such as co.uk, but only like zap.co.uk).
You'll just have to use an auxiliary table (or online source) to tell you which TLD's behave peculiarly like UK's and Australia's -- there's no way of divining that from just staring at the string without such extra semantic knowledge (of course it can change eventually, but if you can find a good online source that source will also change accordingly, one hopes!-).
|
Apparently
Mozilla has a list of known suffixes but in this case I decided to just burn the CPU cycles. The discovered domains could be fed back into the set for quick lookup, but I was still looking at iterating through the TLD list for urls that shouldn't be skipped.
Page name
I found that these
page names can be safely ingored:
// Preceded by "/", end in "/" or "/index.htm[l]?" or ".htm[l]" and
// optionally have "#whatver" or "?whatever" after.
URL_SUFFIX_BLACKLIST_RE = {"terms",
"sustainability",
"legal",
"privacy",
"about",
"legal",
"account",
"contact[-_]?us",
"download[-_]?app",
...
If someone creates a page called
.../about.html that gets skipped it's not the end of the world and, well, that is my about.html page so maybe it's supposed to be skipped.
Though there are a lot of different types of de rigeur pages, they generally follow naming conventions.
Links only
Blogs typically follow the convention of a named page for each post and a monthly roundup of several posts (Wordpress with its ?p=1234 is an exception). The
roundup pages are duplicate/noise/bulky information and therefore should be skipped. That said, they're useful for harvesting links to its constituent pages. So, like ".*\/[\d]{4}\/[\d]{2}[/]?$" on the url will find these pages to stash in the 'ignore' list and harvest for links. The same can be said for home pages and '../links.html'.
PMA
This part of the code required a lot of logic, lists, regexes, and looking at data, but it's probably worthwhile. While my posts list and my ignored list grows with each visit,
the blacklist rules handily cordon off large chunks of the commercial web.
Other things added along the way
Canonical urls
Since www.site.com/my-journey-to-eritrea#hiking is the same as www.site.com/my-journey-to-eritrea is the same as www.site.com/my-journey-to-eritrea?ref=travelguide.com I do what
Google Search Console (and others) do and
query the canonical url, storing the others elsewhere to avoid hitting that page twice.
Data cleaner
Everything about this crawler/scorer evolved as it ran. I'd download pages that would later be excluded by blacklist and so
it was important to re-traverse the manifest and delete the offending files. Likewise my link backlog became cluttered with things like only-occasionally-relevant .edu links. They didn't warrant a blacklist rule, but occasionally flushing .edu and .gov and .ca kept the queue focused. Even more aggressively, I'd retain only things conforming to /yyyy/dd/.
NYI
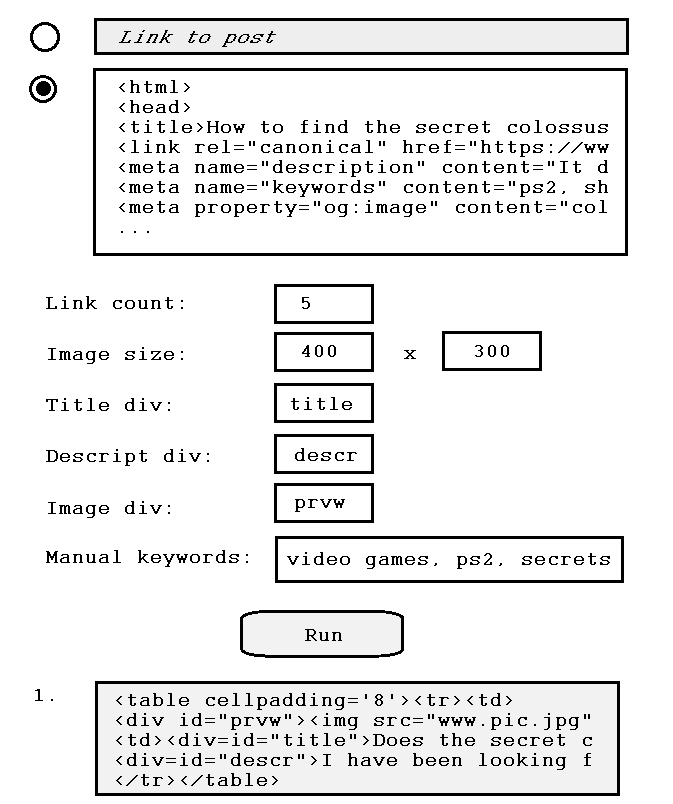
This only works for me and is integrated in my SSG. To actually connect the personal web
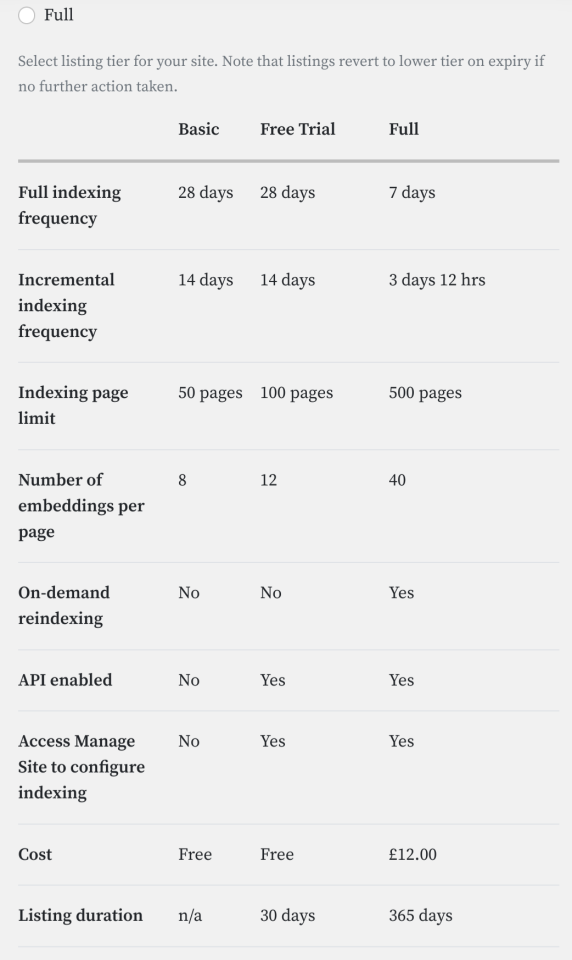
I need a web front end so that any Thomas, Richard, or Harold can easily add external links to their site. It could look something like this:
|
|
|
Submit a post, receive a list of recommendations. A few defaulted values assist with formatting. The results could have report features for 404s, *walls, commercial stuf, etc. |
Seeding and search
Here's a slightly-pruned list of the top
keywords from my crawl corpus at n = 30,000:
Token Count
----------- ------
twitter : 5066
facebook : 3868
rss : 3121
log : 2736
github : 2716
projects : 2463
wordpress : 2461
app : 2319
javascript : 2219
linkedin : 2211
youtube : 2017
newsletter : 1870
games : 1780
mobile : 1648
cookies : 1555
error : 1495
mastodon : 1464
This excludes stopwords, years, stuff like that. Confirming my suspicions from above, the blogosphere seems to talk a lot about the internet, platforms, and web development. That's not great for my posts about PUBG video editing,
nightsurfing, and pool resurfacing - these will either have no links or heavily-shoehorned links. Similar content is out there,
it's just going to take more than 30,000 visits starting from webdevland to get there.
In theory, anyway. In reality I did what any good engineer would do to prepare for an underwhelming demo: I faked it.
Well, not exactly, I simply
seeded my crawl queue with links laboriously found by other means. It solved my immediate problem and hopefully added diversity to my initial link corpus.
Marginalia Search was a good starting point but it had little to nothing about 'Ducati' and 'Fire Emblem Path of Radiance'. A
Hacker News post that
Rob sent me listed a few alternative/indieweb search engines, my experiences weren't great...
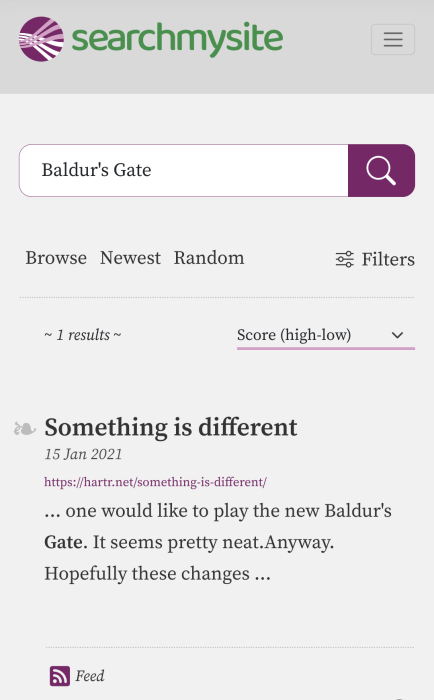
Searchmysite
I asked searchmysite about "Baldur's Gate" hoping it could match any of the older titles or the hot new installment. It yielded a single result.
Perhaps their business model is what's holding them back?
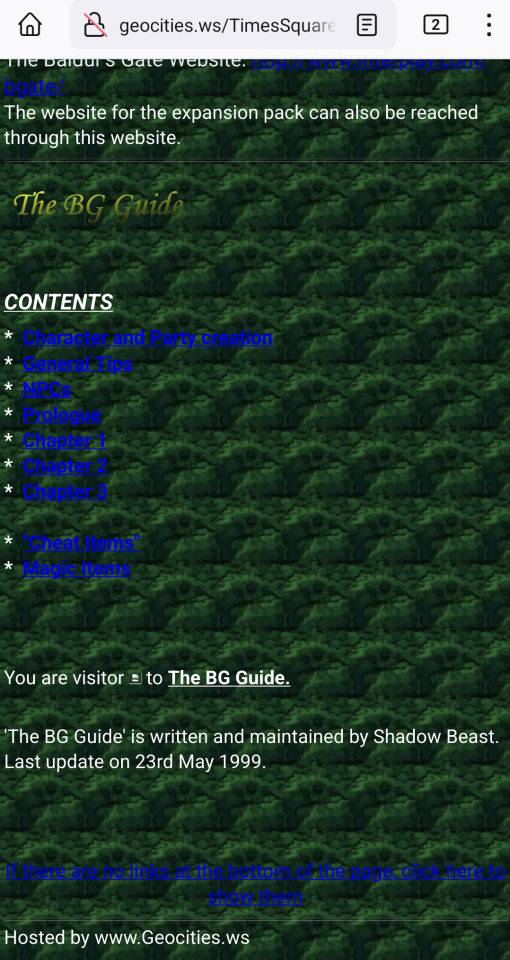
Wiby
Wiby returned more results for "Baldur's Gate" though none showed significant polish or recency. The first result was beautifully/terribly old web and last updated in 1999:
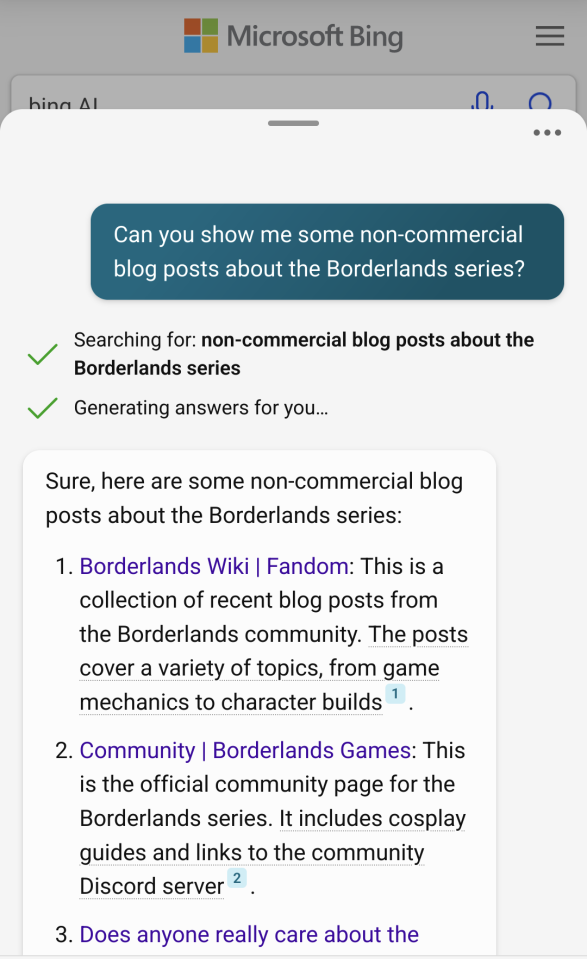
Bing AI search
Enough of this small-time nonsense. Microsoft's investment in OpenAI that
sent Google into red alert would surely meet my needs.
While a ranking algorithm might fail to overcome the onslaught of SEO, an AI-assistant would understand my query. Happily, Bing allows a handful of AI-assisted queries without creating credentials on the site.
I tried my luck with the fertile fields of Borderlands fan-anything,
asking the chatbot for non-commerical blog posts (not entirely redundant, but enough overlap to tell it I meant business). I got:
- A fan wiki with a handful of internal microposts.
- The official forum.
- A Reddit post ranting about how story doesn't matter. Notably the GPT summary reads, "This post on the Borderlands subreddit discusses the importance of the game's story and characters. It argues that the story is what makes the game engaging and memorable".
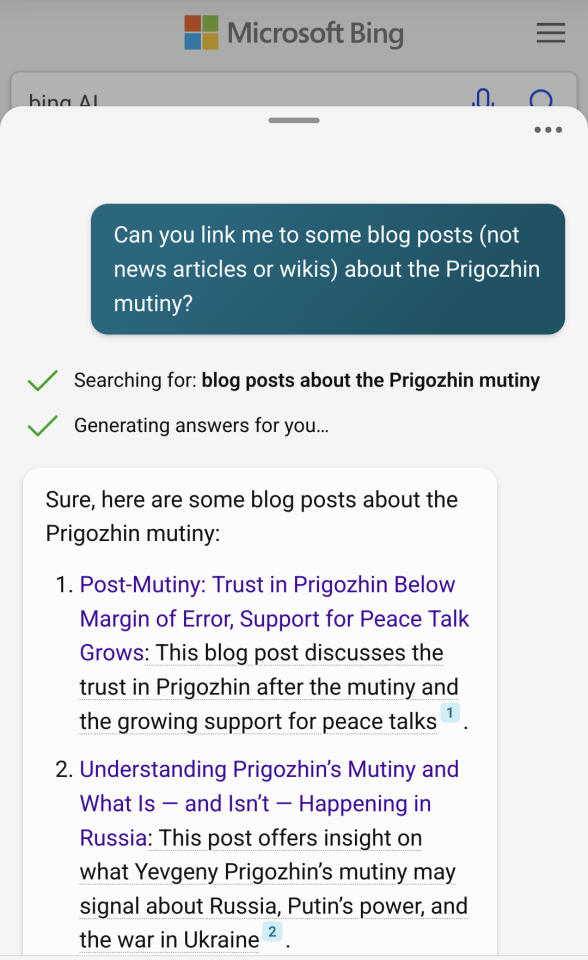
Switching subjects to the Prigozhin rebellion was a bit more productive. Bing provided
a few posts from the geopolitical centers at Harvard and Stanford as well as opinion pieces from the media.
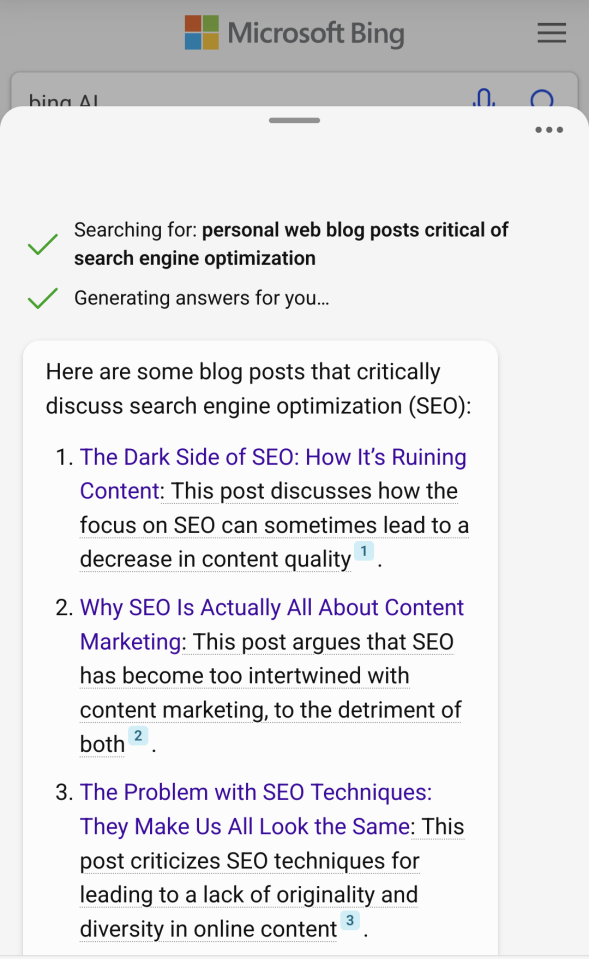
Things got a little weird when I
asked Bing AI to find critical discussions of SEO. I tweaked my query to say "personal web blog posts" hoping this would lead me to some snark or at least content below the major forum/media stratum.
"The Dark Side of SEO" somehow linked to a post titled "Blog SEO Best Practices" with all of the usual formulaic recommendations about keywords and page structure. Weirdly/amazingly the site managed to bait and switch Bing.
The next result which, per Bing AI, "... argues that SEO has become too intertwined with content marketing..." also linked to a hubspot.com post. Again,
it was just a pool of SEO vomit.
I'm not sure how Bing thought the posts were about the opposite of the thing they were about. While the posts contents could change, the urls for both posts are pretty explicit. A funny personal twist: we used to ask
RBB to summarize web links for us. Since native
ChatGPT couldn't fetch webpages,
RBB would do his best using just the url text. That would have actually been more accurate than Bing AI with Search Integration [TM, (c), and (R), probably].
What's next?
I think I'll work on
getting the crawl numbers up and propagating external links to more of my posts.
Some posts from this site with similar content.
(and some select mainstream web). I haven't personally looked at them or checked them for quality, decency, or sanity. None of these links are promoted, sponsored, or affiliated with this site. For more information, see
.












![[+]](https://www.chrisritchie.org/kilroy/archive/2023/10/hct_la.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2015/07/warrior.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2023/07/web.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2019/01/viscera_cleanup_mop.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2023/07/_CRR3746.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2015/02/far_cry_view_00.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2023/07/pool_resurface_concrete.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2020/09/da_bears.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2023/10/aeons_end_legacy.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2017/05/dying_light_stadium.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2023/10/clank_legacy_figurines.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2016/04/division_helo_00.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2023/07/pool_resurface_curing.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2015/11/deezer.jpg){kind=link}