|
|
|
The only graphics in this post are histograms so here's a mildly-relevant AI Poseidon. |
When
we last talked I had done a simple
embeddings implementation for
webpage matching and
web graph entry. I
had to slim the 4,000,000-keyword vocabulary down to a reasonable size for use on a desktop, this was accomplished by using a list of keywords perloined from the
Outer Web trigram corpus.
This rough implementation left me considering
ways to squeeze some more words for semantic matching out of the source data without blowing up the heap or cluttering it with rare terms like 'unomig' (United Nations Observer Mission in Georga) and 'imathia' (part of Macedonia). I was also curious about moving from vector size 100 to 300 to get more data fidelity. A few ideas came to mind:
- Truncate values that are not useful. Specifically, values near zero could perhaps be treated as zero.
- Quantize the default 32-bit float to something smaller. Quantization is a common means to reduce the size of large AI models and applies equally here.
- The obvious one, not using a handful of UTF characters to represent a numeric value.
Since the first two items are lossy,
I needed some sort of giggle test to ensure my code worked as desired and didn't overcook the compression. Embedding math (discussed last time) seemed like a reasonable test so I settled on a few variations on the canonical example, "king + woman = queen". Or maybe it's "king - man = queen". Something like that.
My baseline code from a couple weeks ago used
an embedding vector size of 100 for each term in the 41k-word Outer Web vocabulary (note, I'll refer to this 41k vocabulary through this post). Here are a few sample results with the top five matches listed from left to right:
king + woman: queen monarch mistress lover throne
king - man: monarch prince lion throne warrior
queen + man: king woman princess mistress monarch
Using the same dictionary I generated a
~100mb embeddings file with the size-300 vectors. The results:
king + woman: queen princess monarch mistress bride
king - man: kings woman monarch queen gentleman
queen + man: king woman princess maid monarch
Not the same! So
for a more nuanced application, moving to the bigger vector size would probably be worthwhile. But this required success in one or more of the compression strategies.
Truncation
An embedding looks like:
0 1 2 99
macaroni [0.044 -3.026 1.209 ... -0.180] # "..." is 96 more numbers
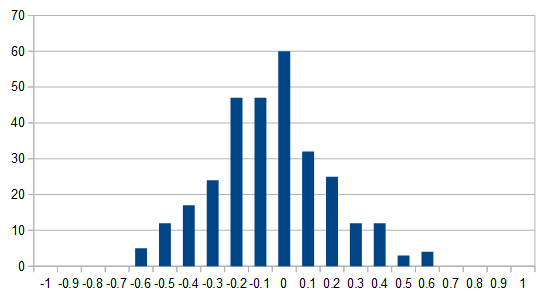
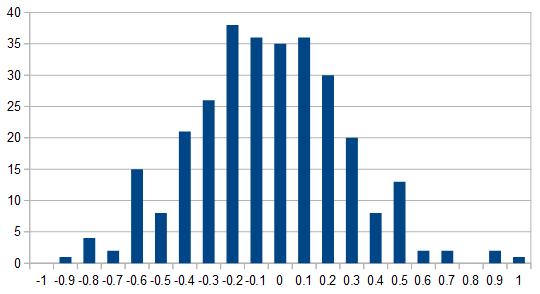
The larger values (positive or negative), 1.209 and -3.026 are strong signal along those dimensions, the values closer to zero (0.044 and -0.180) are weak signal. If toss all of the embedding values for a word in a histogram, you get something gaussianlike:
|
|
|
An example histogram of the values in an embedding. |
Most of the values congregate near 0.0/weak signal which, to busy individuals such as myself, are equivalent to noise and therefore an excellent candidate for truncation. So what if instead of the vector above I have:
macaroni [0.000 -3.026 1.209 ... 0.000]
The embedding is still claimin "I'm super [2] and very, very not [1]" without having much detail about feeling so-so about [0] and [99].
|
|
|
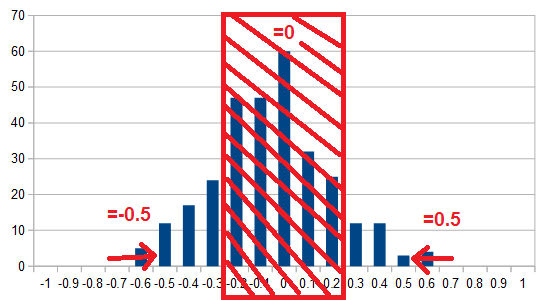
Zeroizing values < 0.2 and setting a max to 0.5. The need for a max comes up in a minute. |
If the vector is represented this way,
I can choose to not store the 0 values just as long as I remember the position of the non-zero values.
macaroni [1]: -3.026 [2]: 1.209
Ignoring all of the numbers in the ellipse, I've shrunk the 'macaroni' vector by half, then added two position index values. In the worst case, this is 8 bytes saved and 4 bytes added.
Okay but can small values actually be truncated?
In my initial implementation I addressed the converse of this question by seeing if high value data indicated semantic importance. It did, in general, but gave me a lot of obscure words. So it wasn't great for choosing words to keep, but it might still be good for choosing values associated with words to ignore.
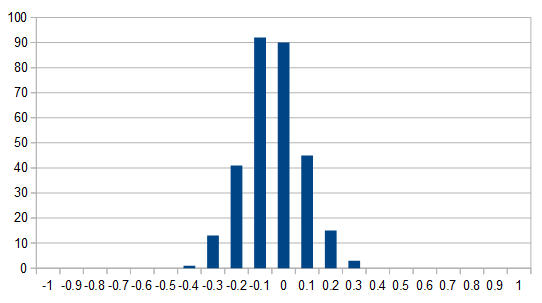
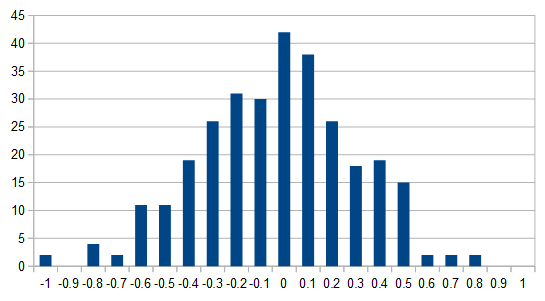
To get some idea of this, I created
a histogram of embedding values for unmeaningful words like 'and' and 'was', they hovered between -0.3 and 0.3:
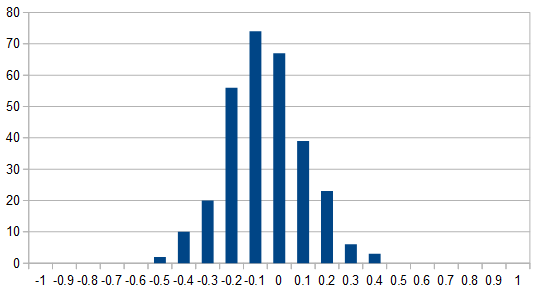
Meanwhile, 'catalytic', 'intergovernmental', and 'reluctance' showed a wider histogram:
This was convincing enough to proceed with an experiment in zeroizing and truncating.
Words that can't be truncated easily
Using my Outer Web dataset,
I listed all of the words where at least 60 of their 100 embedding values exceeded an arbitrary threshold of ±0.35. This truncation thing wouldn't work if most words have very few truncatible vector components. Thankfully, from the 41k only about 200 required more than 60 vector values:
54mm oflag monoamine triassic whitish tonumber palomar verband spay
households motile hollers eigenstates welterweight statistique strikeouts
hispanic srgb forelimbs aaaaaa pounder dormers riemann 35px ssrn
medallists polytope animalia ffff00 geosynchronous webgl markku countywide
tiltrotor dihedral atman coulomb terns 13px latino neowise longlisted
participação finned campagnes scholarpedia mirrorless civilwar isfahan
tengah targetable ffffff prelate lanarkshire median 19mm oboes annaeus
colspan solidworks megabit cellpadding iacr cornus godine parsecs 80px
savez infinitive tomatoes aland pesquisa diverses gazetteer webkit
isnotempty templated mixolydian ssse3 oficial shailesh strasberg quarteto
flycatchers electroweak livros bgcolor dimms flyweight rete honeycombs
makeup evergrande megabits ingenieros floodgap microsd inductance gruyter
florets lightgreen catkins archimedean giang hypotension norepinephrine
antarctic aldrig liên mathworld blancpain wildcards haleakala _main
fermionic subpages 46mm quarks viernes iucn condensates 23mm izquierda
infielder scalar winklevoss name1 name2 valign bookable mollusk 28px
tostring aggregator ochrony pointier 48khz decadal ferodo yalsa proposers
teknologi nikkor lgpl gluons darkgray homomorphic phylogenetics saguaros
90px aquatics significand reuptake honkaku brembo compactflash sepals
slalom volum decoction crüe females orbitofrontal escultura anos sbac
mötley rowspan waisted eigenvalue selatan volcanology battlefleet blazon
penstemon sdhc lemmon census args herpes bioavailability 800mhz serviço
clásica transclusion amstrad direito nonacademic exoplanets quizás boneh
islander nucleocapsid breasted pentax
Quantization
Quantization involves going from a floating point value to an 8-bit, 16-bit, or 32-bit whole number. With a two-byte index field that would support any reasonable vector size, it made sense to
pack the index with a short holding the corresponding value.
Scaling a float to a short requires a min and max. My min was already the arbitrarily-chosen zeroize threshold. Based on an observed 2.5 maximum value, having a max in the 1.5-2.0 range seemed reasonable. So:
macaroni [0.044 -3.026 1.209 ... -0.180] # Original
macaroni [0.000 -3.026 1.209 ... 0.000] # With zeroized
macaroni [1]: -3.026 [2]: 1.209 # Truncated zeros
macaroni [1]: -2.5 [2]: 1.209 # With a max threhsold
The [1]: -2.5 then becomes a tidy 32-bit value that is something like:
And so:
macaroni: 0001fe01 0002804a ... # Truncated and quantized
Performance
I ran the binary storage, truncation, and quantization with the Outer Web data. With a 0.35 threshold and 1.3 max value,
my existing 30mb embeddings file shrank to 6.5mb. My target file size was < 50mb so this result meant I could move to larger vectors and/or a larger dictionary. Unless, of course, the compression made the results suck.
If you'll recall, my pre-compression embedding math examples were this:
king + woman: queen monarch mistress lover throne
king - man: monarch prince lion throne warrior
queen + man: king woman princess mistress monarch
Compression/truncation with a 0.35 theshold and 1.3 max changed some of the results/ordering but the semantics seem to be in the right ballpark.
king + woman: monarch queen throne grandchild mistress
king - man: monarch bastard throne grandchild woman
queen + man: woman king nursemaid monarch princesses
I tweaked the variables to be 0.25 and 1.9:
king + woman: monarch throne queen warrior grandchild
king - man: warrior monarch imposter lover curse
queen + man: king woman bride monarch princess
It's tough to make a confident determination about the goodness of the results, but they certainly weren't prohibitively bad. 'Queen + man' didn't equal 'bicycle'.
Expanding
With the memory savings from compression and truncation, I looked at increasing vector dimensions and vocabulary individually.
First I created a compressed embedding file that only excluded Outer Web stopwords, as opposed to the 41k dictionary that was based on search terms and a whitelist. With vector size 100, 0.28 threshold, and 2.1 max
the 3.25gb raw file shrank to 287mb with 1.8 million words. That's good but uses a larger heap footprint than I'd like, particularly since many of the indexed words are rather obscure.
The other expansion direction was to move to a vector size of 300. Using the Outer Web whitelist, 0.28, and 2.1, the
41k words fit in a very reasonable 16mb.
This meant I could move to 300-value vectors and increase my dictionary size,
so long as I could come up with a list of words between 41k and 1.8M.
A new word list
It made sense to use the Outer Web data to generate a list of keywords for the new embeddings table. First, I wasn't super successful in using the vector data to sort good from bad. Second, since the embeddings would be used to characterize the blogosphere,
using the blogsphere vocabulary would minimize waste.
Since I needed a keyword list bigger than my search index, I wrote a function to step through every page in the Outer Web corpus and create
a list of words that appear in at least four distinct domains. This, intersected with the embedding source list, gave me around 117k keywords and a 43.7mb compressed embedding file.
The math looks good and has some new words:
king + woman: monarch queen kings warrior princess
king - man: kings warrior monarch queen jester
queen + man: king maid monarch beggar majesty
The expanded vocabulary was the difference between knowing what ancient Egyptian kings were called and not knowing:
# 41k words, uncompressed, 100 dimensions:
king + egypt: persia farouk morocco monarch cyprus
# 41k words, uncompressed, 300 dimensions:
king + egypt: persia egyptian kings queen morocco
# 41k words, compressed, 100 dimensions:
king + egypt: monarch farouk hashemite nebuchadnezzar syria
# 117k words, compressed, 300 dimensions:
king + egypt: pharaoh kings retenu persia reign
The new set of embeddings also added 'antoinette' to my vocabulary ('queen + guillotine'). Unfortunately for my lead image, 'ocean + king' = 'atlantic', 'kings', 'queen', 'oceans', and 'tsunami'. 'Poseidon' did not appear.
Some posts from this site with similar content.
(and some select mainstream web). I haven't personally looked at them or checked them for quality, decency, or sanity. None of these links are promoted, sponsored, or affiliated with this site. For more information, see
.





![[+]](https://www.chrisritchie.org/kilroy/archive/2025/04/_CRR6944.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2015/07/warrior.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2025/04/medicine.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2019/01/viscera_cleanup_mop.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2025/04/cappucino_machine.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2020/09/da_bears.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2025/04/_CRR7012.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2015/02/far_cry_view_00.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2025/04/_CRR7008.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2017/05/dying_light_stadium.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2025/04/_CRR6948.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2016/04/division_helo_00.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2025/04/sr_poblano.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2015/11/deezer.jpg){kind=link}