Since it was just the two-ish of us, Jes and I went to the Lodge for Thanksgiving lunch.
Clearing out the upstairs office meant there was some spare pegboard floating around. I replaced a crowded set of coat hooks with the more functional but less attractive paneling.
After several instances of incorrect items (in a time crunch) and rather disappointing streaming availability, I kicked Prime to the curb. It's covid, so I replaced vanilla Prime HBO with HBO Max.
The wheel
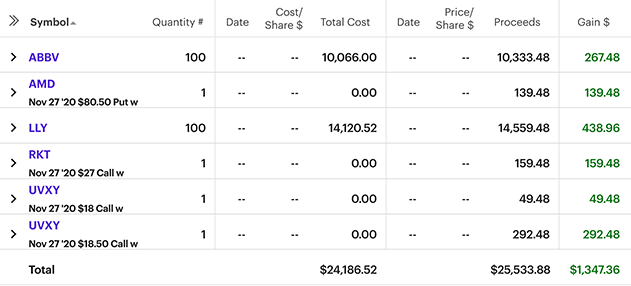
Wheel trading (bouncing between cash-secured puts and covered calls) has been a fun hobby with better profit potential than GME YOLOs. The story of the above:
ABBV: I bought 50 shares a few months back at ~$97 speculating on a covid treatment/vaccine (the company is pretty well established). Rounded it out to 100 at ~$101/share and sold a 4DTE $103 covered call for $35. $267 is barely worth typing about, but it's a healthy 2.5% return in (kind of) a week.
AMD: Wanted to get back in to AMD, but the CSP expired and netted $139.48 by setting aside $8,000 for a week or two.
LLY: A pharma heavy hitter and recurring name in the covid news, the cc netted $438.
RKT: Their IPO rocketed from under $20 to $30 and then settled back in the $20 range. When it was in the low 20s and still trading with a lot of volume, I sold a month-ish cc to make the price decline less painful. Still bullish about RKT in the long run.
UVXY: I bought UVXY months ago and have held onto it. The 2008 in me expects a rug pull, the rest of me sees it as a wise hedge against the only risk in wheel trading. In the mean time, selling calls on some of the position has helped mitigate the price drop.
PUBG un-RIP(?)
A few months back I eulogized PUBG. Turns out, covid combined with a lack of attractive alternatives brought the squad back. Not much has changed in the game, we've learned to live with the bots and appreciate the game's marginally better stability.
Neural style transfer, but TensorFlow this time
I meandered back into neural style transfer over football. I'd last left it with my DL4J experimentation, which notably didn't have hardware acceleration. Since the Keras sample code was easy to hit 'go' on, I tried that.
For this exercise I went with:
Content: Rossi on a Ducati at Laguna
Style: Hunter Thompson on a Ducati in Colorado, from the brush of Ralph Steadman.
Same same
Naturally, a 1060 is much quicker than a Core i7. But I was treated to largely the same results as before.
The algorithm tends toward wavy lines in areas of low detail and seems to produce similar images regardless of style. Unlike the DL4J code that required VGG19-size (224x224) images, this one does scaling, for better or worse.
Scaling up
It didn't take long to modify the example to do tiles of a full res image. The tile boundaries are obvious and could be fixed inelegantly with photoshop and elegantly with feathering and staggering. I also found a blog post (whose url I have since lost) that recommended a few things:
Use mean absolute delta vs mean squared delta for calculating loss (allow for some artistic liberty).
Use ADAM instead of BFGS. I couldn't figure out how to do this but didn't try too hard.
For style layers, use the first convolutional layer of each block; apparently the tutorial uses just the top layers. I decided to switch this up a bit and made each of the recommended style layers 80% likely to be used in the loss calculation.
As long as I was tiling the content/output, it made sense to apply another lesson and sample various portions of the style image. That is, the naive method is to take two 224x224 images and combine them, so you have crop/scale both content and style images to a small square. Scaling down means that whatever style you have quickly becomes lost - e.g. a 10x13 brushstroke make be condensed to 2x3. Cropping the style image means you're only looking at a portion of the art - so your Maison Pour Erotomane may be all car and no horse.
So my next revision applied a random 224x224 style square to each tile of the content.
Implementing an outer loop meant working out something that I hadn't yet done - loading incremental output. I think I accomplished this by initializing the initial guess field of fmin_l_bfgs_b() to the last value rather than the content. The algorithm still computes content/style loss from the original images, but can now be checkpointed.
Each progressive iteration shows more and more artistic stylization that quickly becomes pretty abstract. You also see the hard tile boundaries soften as I introduced a small translation to each input value.
You can also see the entire image bounce between styles as the random sample from the Steadman image changes from one section to the next. This, of course means progressive iterations move between 'substyles' of the style image. Numerically, it means trying to find the global minimum on a moving target. From a graphic art perspective, this creates a set of image variations that can be manually or automatically blended to a final product.
Style match
The thought occurred to me that there are tiles in the style image that might be more appropriate for a given content tile. Heuristics come to mind, i.e. selecting a tile from the style image based on its fitness for the content; matching color, matching contrast, etc. Ultimately though, it seemed like the easiest and best(?) approach would be to let loss make that determination. The optimization of each tile would sample a number of sources and only retain best results.
In the spirit of increasing the number of 'style matches' for a given square of content, I added a couple more Steadmans to the random sampling. The output looked like this:
Processing tile: ( 0 , 0 ) at ( 16 , 0 )
Style source 0
Loss: 203719060.0
Using result
Style source 1
Loss: 200921020.0
Using result
Style source 2
Loss: 164412600.0
Using result
Style source 3
Loss: 197183180.0
Style source 4
Loss: 155275980.0
Using result
Processing tile: ( 0 , 1 ) at ( 16 , 238 )
Style source 0
Loss: 249554060.0
Using result
Style source 1
Loss: 214680510.0
Using result
Style source 2
Loss: 179050400.0
Using result
Style source 3
Loss: 198226380.0
Style source 4
Loss: 183831140.0
And like that, football was over. I ran the code enough to see a different-but-consistent style applied to my image set. The output is ultimately beholden to iteration count and content/style weight hyperparameters.
The code, as it is right now:
'''Neural style transfer with Keras. Modified as an experiment.
# References
- [A Neural Algorithm of Artistic Style](http://arxiv.org/abs/1508.
06576)
'''
from __future__ import print_function
from keras.preprocessing.image import load_img, save_img, img_to_array,
array_to_img
import numpy as np
from scipy.optimize import fmin_l_bfgs_b
import time
import random
import glob
import argparse
import os.path
from os import path
from keras.applications import vgg19
from keras import backend as K
def preprocess_image(img):
img = img_to_array(img)
img = np.expand_dims(img, axis=0)
img = vgg19.preprocess_input(img)
return img
def deprocess_image(x):
if K.image_data_format() == 'channels_first':
x = x.reshape((3, side_length, side_length))
x = x.transpose((1, 2, 0))
else:
x = x.reshape((side_length, side_length, 3))
# Remove zero-center by mean pixel
x[:, :, 0] += 103.939
x[:, :, 1] += 116.779
x[:, :, 2] += 123.68
# 'BGR'->'RGB'
x = x[:, :, ::-1]
x = np.clip(x, 0, 255).astype('uint8')
return x
def gram_matrix(x):
assert K.ndim(x) == 3
if K.image_data_format() == 'channels_first':
features = K.batch_flatten(x)
else:
features = K.batch_flatten(K.permute_dimensions(x, (2, 0, 1)))
gram = K.dot(features, K.transpose(features))
return gram
# the "style loss" is designed to maintain
# the style of the reference image in the generated image.
# It is based on the gram matrices (which capture style) of
# feature maps from the style reference image
# and from the generated image
def style_loss(style, combination):
assert K.ndim(style) == 3
assert K.ndim(combination) == 3
S = gram_matrix(style)
C = gram_matrix(combination)
channels = 3
size = side_length * side_length
return K.sum(K.square(S - C)) / (4.0 * (channels ** 2) * (size ** 2))
# an auxiliary loss function
# designed to maintain the "content" of the
# base image in the generated image
def content_loss(base, combination):
return K.sum(K.square(combination - base))
# edge detector - sum edges will be how busy it will look
def total_variation_loss(x):
assert K.ndim(x) == 4
if K.image_data_format() == 'channels_first':
a = K.square(
x[:, :, :side_length - 1, :side_length - 1] - x[:, :, 1:, :
side_length - 1])
b = K.square(
x[:, :, :side_length - 1, :side_length - 1] - x[:, :, :
side_length - 1, 1:])
else:
a = K.square(
x[:, :side_length - 1, :side_length - 1, :] - x[:, 1:, :
side_length - 1, :])
b = K.square(
x[:, :side_length - 1, :side_length - 1, :] - x[:, :
side_length - 1, 1:, :])
return K.sum(K.pow(a + b, 1.25))
def fidelity_loss(x, y):
assert K.ndim(x) == 3
assert K.ndim(y) == 3
if K.image_data_format() == 'channels_first':
x_g = K.sum(x[:3, :, :])
y_g = K.sum(y[:3, :, :])
return K.square(x_g - y_g)
else:
x_g = K.sum(x[:, :, :3])
y_g = K.sum(y[:, :, :3])
return K.square(x_g - y_g)
# Experiment with luminance
#if K.image_data_format() == 'channels_first':
# x_g = np.dot(x[0, :3, :, :], [0.2989, 0.5870, 0.1140])
# y_g = np.dot(y[0, :3, :, :], [0.2989, 0.5870, 0.1140])
# return K.square(x_g - y_g)
#else:
# x_g = np.dot(x[0, :, :, :3], [0.2989, 0.5870, 0.1140])
# y_g = np.dot(y[0, :, :, :3], [0.2989, 0.5870, 0.1140])
# return K.square(x_g - y_g)
# Returns style layers - this is the default (all), I experimented with
dropping random ones
def get_random_style_layers():
return ['block1_conv1', 'block2_conv1', 'block3_conv1', 'block4_conv1',
'block5_conv1']
def get_random_crop(image, width, height):
'''Returns a random subimage with the given width and height.'''
# Crop to width and height, if specified.
x = 0
if width is not None and width != image.width:
x = int(random.randrange(image.width - width))
y = 0
if height is not None and height != image.height:
y = int(random.randrange(image.height - height))
if x != 0 or y != 0:
box = (x, y, x + width, y + width)
image = image.crop(box)
return image
def eval_loss_and_grads(x):
if K.image_data_format() == 'channels_first':
x = x.reshape((1, 3, side_length, side_length))
else:
x = x.reshape((1, side_length, side_length, 3))
outs = f_outputs([x])
loss_value = outs[0]
if len(outs[1:]) == 1:
grad_values = outs[1].flatten().astype('float64')
else:
grad_values = np.array(outs[1:]).flatten().astype('float64')
return loss_value, grad_values
def random_style_tile():
image = style_images[random.randrange(len(style_images))]
return get_random_crop(image, side_length, side_length)
class Evaluator(object):
def __init__(self):
self.loss_value = None
self.grads_values = None
def loss(self, x):
assert self.loss_value is None
loss_value, grad_values = eval_loss_and_grads(x)
self.loss_value = loss_value
self.grad_values = grad_values
return self.loss_value
def grads(self, x):
assert self.loss_value is not None
grad_values = np.copy(self.grad_values)
self.loss_value = None
self.grad_values = None
return grad_values
side_length = 224 # VGG19 is 224x224x3
# Iteration hyperparameters (modify these)
iterations_per_image = 10 # Number of image traversals
samples_per_tile = 3 # Number of style tiles to try per iteration
iterations_per_sample = 10 # Number of style transfer iterations per
sample
# Use all png files from the style subdirectory, random 224 squares will
be used
# from these files to perform style transfer - so image size should be
# approximately the dimensions of the content.
style_files = glob.glob('style/*.png')
file_id = random.randrange(696969)
# Load content.png, the size of this image will significantly impact run
time.
content_image = load_img('content.png')
content_width, content_height = content_image.size
# Load style images.
style_images = []
for style_name in style_files:
style_image = load_img(style_name)
style_images.append(style_image)
# If this setup was run previously, use the existing output image.
if (os.path.isfile('last.png')):
output_image = load_img('last.png')
else:
output_image = load_img('content.png')
# Compute the tile count/step size. There will be overlap and it should
# be a good thing.
x_tiles = int(content_width / side_length)
if (content_width % side_length != 0):
x_tiles += 1
x_step = int(content_width / x_tiles)
y_tiles = int(content_height / side_length)
if (content_height % side_length != 0):
y_tiles += 1
y_step = int(content_height / y_tiles)
feature_layers = get_random_style_layers()
print('Style layers: ' + str(feature_layers))
# Number of times to cover the entire image (optimize each tile)
for image_iteration in range(iterations_per_image):
print('Iteration: ', image_iteration)
# Randomize hyperparameters because I don't know what good values are.
# Modify these/make them fixed.
total_variation_weight = random.uniform(0.001, 0.5)
style_weight = random.uniform(0.001, 0.5)
content_weight = random.uniform(0.001, 0.5)
fidelity_weight = random.uniform(0.001, 0.5)
# Bump the tile a random value to do a smoother stitch.
x_jitter = int(random.randrange(-16, 16))
y_jitter = int(random.randrange(-16, 16))
# Iterate over each image tile.
for x_tile in range(x_tiles):
for y_tile in range (y_tiles):
x_start = (x_tile * x_step) + x_jitter
y_start = (y_tile * y_step) + y_jitter
# Post-jitter boundary check.
if (x_start < 0):
x_start = 0
if (y_start < 0):
y_start = 0
if (x_start + side_length > content_width):
x_start = content_width - side_length - random.randrange(1,
16)
if (y_start + side_length > content_height):
y_start = content_height - side_length - random.
randrange(1, 16)
print(' Processing tile: (', x_tile, ', ', str(y_tile), ')
at (', x_start, ', ', y_start, ')')
box = (x_start, y_start, x_start + side_length, y_start +
side_length)
tile_content = content_image.crop(box)
base_image = K.variable(preprocess_image(tile_content))
best_loss = -1
# For each tile, sample the random portions of the style
image(s) and choose
# the best of the lot.
for i in range(samples_per_tile):
print(' Trying tile ', i)
tile_style = random_style_tile()
evaluator = Evaluator()
tile_output = output_image.crop(box)
# run scipy-based optimization (L-BFGS) over the pixels of
the generated image
# so as to minimize the neural style loss
x = preprocess_image(tile_output)
style_reference_image = K.
variable(preprocess_image(tile_style))
if K.image_data_format() == 'channels_first':
combination_image = K.placeholder((1, 3, side_length,
side_length))
else:
combination_image = K.placeholder((1, side_length,
side_length, 3))
# combine the 3 images into a single Keras tensor
input_tensor = K.concatenate([base_image,
style_reference_image,
combination_image], axis=0)
# Reinitialize VGG19. There's probably a way to do this
once and
# improve performance.
model = vgg19.VGG19(input_tensor=input_tensor, weights=
'imagenet', include_top=False)
outputs_dict = dict([(layer.name, layer.output) for layer
in model.layers])
# combine these loss functions into a single scalar
loss = K.variable(0.0)
layer_features = outputs_dict['block5_conv2']
base_image_features = layer_features[0, :, :, :]
combination_features = layer_features[2, :, :, :]
loss = loss + content_weight *
content_loss(base_image_features, combination_features)
for layer_name in feature_layers:
layer_features = outputs_dict[layer_name]
style_reference_features = layer_features[1, :, :, :]
combination_features = layer_features[2, :, :, :]
loss = loss + (style_weight / len(feature_layers)) *
style_loss(style_reference_features,
combination_features)
loss = loss + total_variation_weight *
total_variation_loss(combination_image)
loss = loss + fidelity_weight *
fidelity_loss(combination_features, base_image_features)
# get the gradients of the generated image wrt the loss
grads = K.gradients(loss, combination_image)
outputs = [loss]
if isinstance(grads, (list, tuple)):
outputs += grads
else:
outputs.append(grads)
f_outputs = K.function([combination_image], outputs)
# With this content/style combo, use the style transfer
algorithm.
for i in range(iterations_per_sample):
x, min_val, info = fmin_l_bfgs_b(evaluator.loss, x.
flatten(),
fprime=evaluator.
grads, maxfun=20)
print(' Loss[', i, ']: ', min_val)
# If this is the first style sample or it's better than
the last
# use this output.
if (best_loss == -1 or min_val < best_loss):
print(' Updating from prev: ', min_val, ' < ',
best_loss)
img = array_to_img(deprocess_image(x.copy()))
output_image.paste(img, (x_start, y_start))
best_loss = min_val
# Reset the back end
K.clear_session()
fname = 'output_' + str(file_id) + '_%d.png' % image_iteration
print(' ->', fname)
save_img(fname, output_image)
save_img('last.png', output_image)
Fantasy
25-8 on aggregate going into this wild weekend of Jacksonless Ravens, QBless Donkeys, and a Thursday-Tuesday weekend.
Week
d'san andreas da bears
- Medieval Gridiron -
Covid-20
- Password is Taco -
Dominicas
- Siren -
1
Danville Isotopes
110.8 - 72.5 W (1-0)
Black Cat Cowboys
155.66 - 78.36 W (1-0)
TeamNeverSkipLegDay
136.24 - 107.50 W (1-0)
2
Screaming Goat Battering Rams
119.9 - 105.9 W (2-0)
[Random UTF characters resembling an EQ]
115.50 - 115.74 L (1-1)
Dem' Arby's Boyz
94.28 - 102.02 L (1-1)
3
Nogales Chicle
106.5 - 117.8 L (2-1)
Circle the Wagons
100.42 - 90.02 W (2-1)
JoeExotic'sPrisonOil
127.90 - 69.70 W (2-1)
4
Britons Longbowmen
122.9 - 105.1 W (3-1)
Staying at Mahomes
123.28 - 72.90 W (3-1)
Daaaaaaaang
138.10 - 108.00 W (3-1)
5
Toronto Tanto
105.0 - 108.2 L (3-2)
Robocop's Posse
111.32 - 134.26 L (3-2)
Alpha Males
86.20 - 76.12 W (4-1)
6
Only Those Who Stand
108.2 - 66.7 W (4-2)
KickAssGreenNinja
65.10 - 84.02 L (3-3)
SlideCode #Jab
71.60 - 53.32 W (5-1)
7
San Francisco Seduction
121.7 - 126.4 L (4-3)
Ma ma ma my Corona
118.22 - 84.20 W (4-3)
G's Unit
109.20 - 92.46 W (6-1)
8
LA Boiling Hot Tar
116.2 - 59.4 W (5-3)
Kamaravirus
118.34 - 109.94 W (5-3)
WeaponX
113.14 - 85.40 W (7-1)
9
SD The Rapier
135.0 - 90.8 W (6-3)
C. UNONEUVE
117.80 - 90.16 W (6-3)
Chu Fast Chu Furious
128.28 - 59.06 W (8-1)
10
West Grove Wankers
72.9 - 122.8 L (6-4)
Pug Runners
98.90 - 77.46 W (7-3)
NY Giants LARP
75.24 - 75.06 W (9-1)
11
SF Lokovirus
127.9 - 87.1 W (7-4)
Bravo Zulus
116.34 - 45.50 W (8-3)
HitMeBradyOneMoTime
107.42 - 89.22 W (10-1)
12
Danville Isotopes
154.7 - 64.1*
Forget the Titans
57.04 - 99.74*
TeamNeverSkipLegDay
122.68- 91.12*
Very impressive. Please note that any appearance of danger is merely a device to enhance your testing experience.
The covid surge that everyone expected after Thanksgiving has hit. Jes is busy at work. I can get by with games, streaming, jogging, and taking the dog out.
Reflecting on investments and Warren B. Some sunset surf shots, video games, and AI image stylization.
Related / external
Risky click advisory: these links are produced algorithmically from a crawl of the subsurface web (and some select mainstream web). I haven't personally looked at them or checked them for quality, decency, or sanity. None of these links are promoted, sponsored, or affiliated with this site. For more information, see this post.



































![[+]](https://www.chrisritchie.org/kilroy/archive/2020/09/da_bears.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2015/07/warrior.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2020/09/draft.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2015/02/far_cry_view_00.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2020/09/virus.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2016/04/division_helo_00.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2020/08/ror2_poon.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2017/05/dying_light_stadium.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2020/08/ror2_bubble.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2015/11/deezer.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2020/09/margin_call.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2016/08/witches_lair.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2020/07/cases_20200704.png){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2015/02/far_cry_items.jpg){kind=link}