Jan 1's covid spike looked bad, but case rates have just kept going. As such, here's a long post that covers fractals, autoencoders, style transfer, and some vidya.
Burning ship
Burning ship fractal, looking like it sailed up the Seine and parked in front of a big gothic cathedral.
I've never done a fractals exercise before, but wanted to give it a go to see if it could be used for graphics stuff. Based on the name and pseudocode, Burning Ship looked like a fun/easy one to try. There are some pretty cool fractals algorithms that do recursive computations, but this one is just an (x, y) -> value computation. The code amounts to this:
Non-standard types used here... RGBPixel is just a personal implementation of an rgb value with helpers. Location (of the viewer) is just a glorified struct with values capturing zoom and center, and I'm not entirely sure I calculated these correctly.
"Zoom and center?" Yeah so the fractal plots a fixed image where you can infinitely pan and zoom to see interesting stuff. Like this:
It was a fun mini-project, but has pretty limited application to image stylization without a lot of code/creativity. There is some implementation left to the user in terms of converting a 0.0-1.0 value to an RGB value, so I opted for the closest I could come up with to the colors of an actual burning ship.
Got tiling going (to drag an autoencoder over a larger image). Here.
Applied the technique to reproduce graphics filters. Here.
For everything south of here, I used various implementations of tiling - from hard checkboard stitch to edge feathering. So if you see harsh edges, it's just because I didn't throw as many cycles at that image.
Input image, compare to the AE-generated image above that looks mildly-stylized.
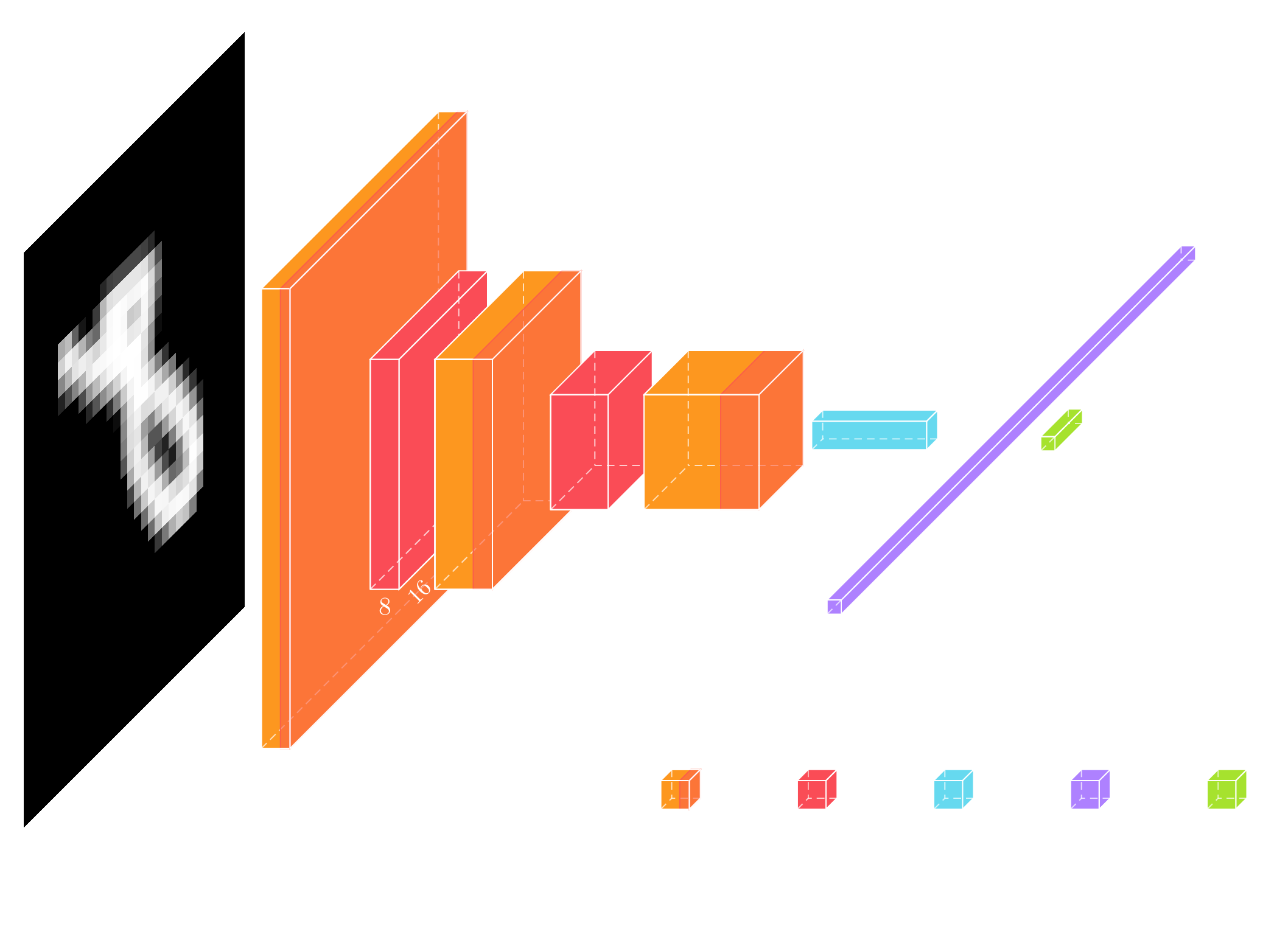
My second AE implementation was pretty straightforward (code below) and didn't require the model to do much work to remember images. I trained it with adam and MSE. Notice it's not really an autoencoder because there's no latent/flat layer.
Model #5 attempted to introduce a convolutional bottleneck by putting two eight-kernel layers of sizes 7 and 13 in the middle of the network. The idea was to create kernels that are estimations of large features and let the smaller/more numerous kernels downstream reconstruct that as it saw fit. Once again, it's pretty close to the source image.
Along the way I added tweaks to support non-RGB color spaces (individually) for input and output. Model #6 stacked convolutional layers of 3, 5, 7, 9, 5, 3 with some dense layers and noise/dropout. Again it looks like a non-blocky, compressed image (which is autoencodery!).
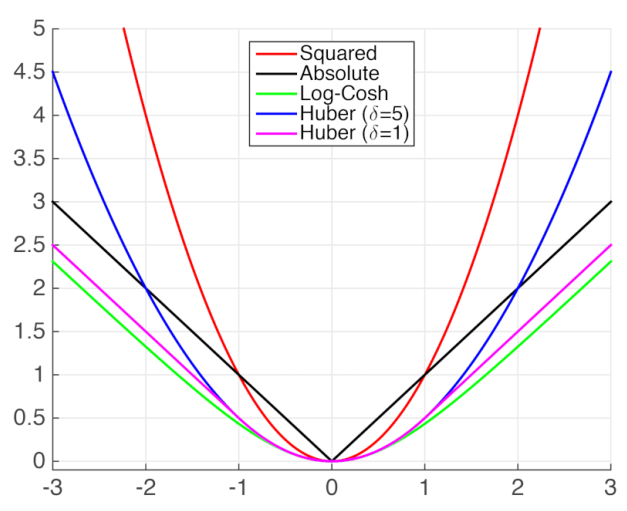
Using model #6 in hsv mode, I swapped MSE loss calculation out for Huber, which (I think) is like MSE but doesn't punish large differences quite so much. I think this one was trained pretty lightly, but shows some a less-perfect attempt at image reconstruction.
But what about real bottlenecking?
Autoencoders are all about shrinking the input, squeezing it through latent space, and transpose convolving it up to the input size. For whatever reason, I haven't had much success with this. I tried the standard convolve-maxpool-2x2-repeat to shrink the input space and allow the inner kernels to 'see' more of the image. Then it was reconstructed using transpose convolution. My output resembled a checkerboard that seemed to correlate with the latent layer, so like the transpose layers weren't doing much?
I switched things up a bit and did a single maxpool 8x8, no flattening, and an 8x transpose convolution to restore the original dimensionality. Once again, the output looked like a bad upscale.
I traded out the maxpool-transpose strategy for strided convolution and upsampling followed by convolutions (in place of transpose). The output was less pixelated, but still it seemed like the generative half of the network wasn't being particularly helpful.
Back to variations on a convolutional theme
Some output of the models talked about in the earlier section.
Input modification
While bottlenecking the autoencoder is one way to force it to learn rather than remember, giving it dirty input is also useful. While supervised learning often involves finding, buying, or making labeled datasets, this was simply a matter of throwing my substantial Java graphics library at manipulating the 'good' images.
Finding the right amount and type of artifact-generation is not straightforward, so I just WAGged it with two approaches:
Median filtering and desaturating various rectangular areas in the image.
Introducing small artifacts like areas of noise, unfilled rectangles, and other color manipulations.
Top image is a partially blurred/desaturated version of the one used previously. The rest of the images are autoencoder outputs, using the same models from before.
The results showed that the autoencoder was trying to fix those areas and perhaps would be more successful with more/better training. On the other hand, this wasn't too far off of some upscaling/inpainting examples that I've seen, with the exception of GANs. GANs seem to do a lot better at inventing plausible images but often create something that looks right until you realize, say, the rose petal has thorns. That said, generating a rose petal with thorns sounds pretty neat. Well, it's not the most sophisticated symbolism, but I'm not going to judge the visual metaphors of an hours-old artificial intelligence.
I found that my more successful implementations were bottoming out (loss-wise) after a few hours of training. I mentioned earlier that I experimented with Huber loss since I'm not so much looking for (nor computationally equipped for) photorealistic image reproduction. I think it'd be neat to have a content-aware style filter, so a single pixel deviating from its expected value need not be punished with squared error.
And with more thought, it felt like in a small image with 65k pixels, I might be reaching a point of trading loss in one place for another. Beyond Huber, I had a few thoughts on this. One consideration is that losses can be whatever you want so it would be reasonable to supplement MSE or Huber with a more forgiving loss computation, e.g. those same metrics run on a median-filtered image might allow spatially-close guesses to be rewarded even if they're not pixel-perfect.
I ran into a wall when I looked to do anything more complex than adding precanned loss functions. It's probably not too difficult, but between effort level, Python-tier documentation, and miserable search results, I simply did not go very far down that path. And even when I did the simple thing of setting loss to MSE + KL (a cool measure of entropy introduced), running the autoencoder later gave me an exception that the custom loss function wasn't captured in the model (and somehow needed for a forward pass).
I'm sure a lot of this is just my unfamiliarity with the framework. I'll keep at it, since I think loss calculation can be pretty important to align with what you want out of your network. Ideas:
Already mentioned, median filter the predicted/true matrices to not punish pixel-by-pixel error quite so hard.
Weight pixel brightness accuracy over hue/saturation.
Supplement an MAE or Huber loss with MSE on sampled areas.
Use KL to encourage the network to either simplify or complicate.
Fiddle with coefficients of multi-parameter losses.
Style transfer
The input and three output images manually combined to produce the image at the top of the post. Style images used to produce each are shown. This wasn't particularly well-baked, you can see the per-tile variation that could be normalized with more passes.
To recap neural style transfer, it's a nontraditional machine learning technique that feeds a content and style image into a popular classification network, then modifies the input image to minimize inaccuracy between the two. It was one of those popular medium.com things five or so years ago, but isn't quite as exciting as the hype.
I modded the neural style transfer demo code that works on 224x224 images to instead apply the algorithm to as many tiles as needed to cover a larger image.
I let the algorithm try a sampling of different input areas from the style image to let it decide which part it could best optimize.
I decided style transfer is an interesting, content-sensitive method for photo stylization, but requires postprocessing to blend it nicely. It's also time/compute-intensive and thereby only suitable for sparing use. In contrast, styling with traditional deep learning methods is costly to train but quick to execute.
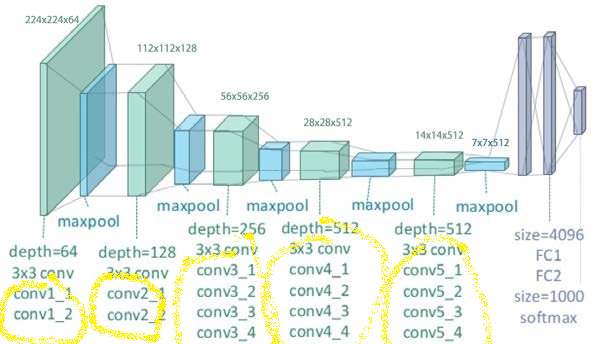
The style transfer image generation technique chooses various so-called 'style layers' from the VGG19 convolutional blocks. I previously pulled on the thread of randomly dropping some of these layers just to see what would happen. I didn't go far down that path, but autoencoder training gave me some time to dive back in. My variation on the previous idea was to use a completely random selection of convolutional layers to be the style component.
Results
Using that Horizon Zero Dawn screenshot from the autoencoder section (first image below) with a brush style input, I got a pretty wide variety of results. Note the tiling created some hard seams that could be fixed with additional iterations.
To see the layers used, look at the image names, e.g. b2c2b5c2 used block2_conv2 and block5_conv2.
Switching it up to the Kanagawa wave and Vale exiting the 'Screw:
Some additional run parameters:
Looked at four different style tiles to find the best one.
Descended on each style tile for 14 iterations.
Content was weighted about 100 times more than style.
Again, as standalone images these are fairly meh, but even with some mild blending back to the original image you can produce neat stylizations:
ME3:LE - Leviathan, Omega, and Tuchanka
Spoilers to follow...
Leviathan DLC
So I had a pretty good idea that Leviathan was about meeting the Reapers' makers, but for some reason I was pikachufaced by them being huge, Reaper-shaped, and aquatic. The confrontation/conversation was pretty neat if you ignore that part of the premise is negotiating them out of complacence and into being a minor war asset. And while the Leviathan/Reaper/Prothean lore is all worth listening to, this DLC and the Javik one exhaust the great mysteries of the ME universe (except, of course, why the council refuses to believe anything). Some of it could have been left to speculation.
Leviathan could have been the ME2 plot; track down the Reaper progenitors to find out how to survive the cycle.
Omega DLC
I guess Cerberus (it's always them) took Omega to do reapery stuff and Aria wants it back. Kind of a blah plot, it's amazing how the galaxy's Q-Anon can manage to take over colonies, lawless strongholds, and even the Citadel. Aria reclaiming her throne is yet another, "hey guys, half the galaxy is being destroyed, do we really have time for this?" I can successfully tell myself the ending invalidates it all anyway, so I might as well enjoy it. So while this story arc isn't particularly important or interesting, the setting and characters are pretty great.
The story is a bit heavy-handed at driving home the idea that Nyreen Kandros is the anti-Aria, but she's otherwise a neat frenemy in her short screen time.
Speaking of heavy-handed. "Hey, how do we make this villain seem smart? Like *real* smart? Oh I know, show him playing chess!"
Act II
Tuchanka is saved, Victus is vindicated, and Mordin is a damned hero :'(
And yeah, the Indocrinated, Illusive Man managed to pull a January 6th on the Citadel. It's not nonsensical, but more and more I feel the series would have been a lot better off if Cerberus had remained a minor plot arc in ME1. Instead, they are the Cersei to the Reapers' White Walkers, except this Cersei is absolutely everywhere and seems to have infinitely deep pockets despite how failure-prone she is.
In contrast, the Geth-Quarian and Krogan-Everyone arcs are pretty solid.
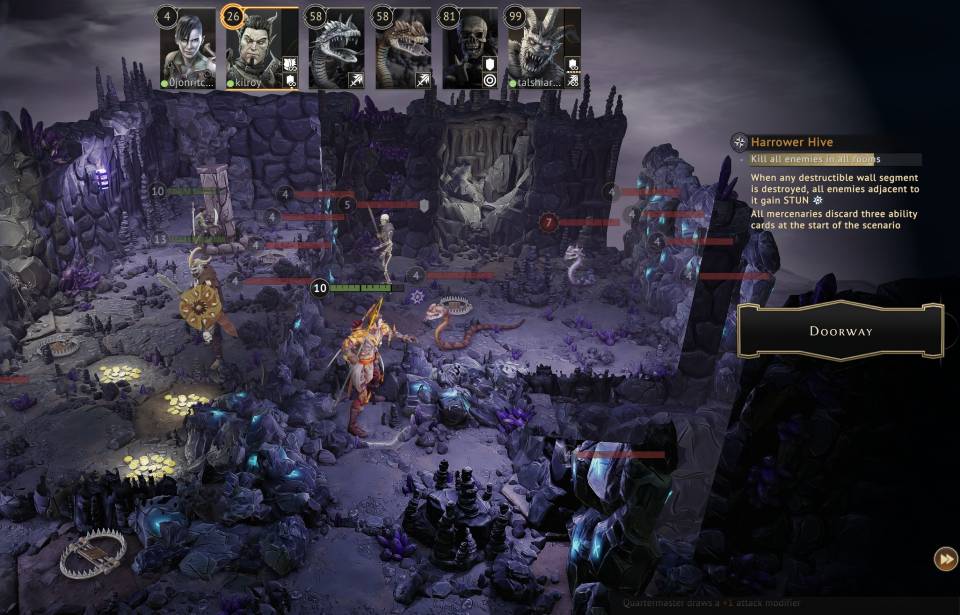
Gloomhaven
A Party Has No Name has gotten a few sessions in recently. Not liking the early-game Spellweaver, I was happy to hit my easy retirement goal (200 wingwangs) and unlock the Quartermaster. He's always prepared and kind of looks like a Bee. So he's Prepared Bee. He's trustworthy, loyal, helpful ... you get the picture.
The party hit some difficulties with early scenarios playing on hard. We dialed it back to normal and have beaten one, breezed through another, and gotten wrecked by a boss.
Russia stages forces on its Ukrainian border and a Redditor connects the Putin-Manafort-Burisma dots. I hunt treasure in Far Cry 6 and hit the final stretch of the Mass Effect trilogy. KO and Connie play on words in a language I do not understand.
Since it was just the two-ish of us, Jes and I went to the Lodge for Thanksgiving lunch.
Related / external
Risky click advisory: these links are produced algorithmically from a crawl of the subsurface web (and some select mainstream web). I haven't personally looked at them or checked them for quality, decency, or sanity. None of these links are promoted, sponsored, or affiliated with this site. For more information, see this post.
In the Latent Diffusion Series of blog posts, I'm going through all components needed to train a latent diffusion model to generate random digits from the MNIST dataset. In this first post, we will tr
In this tutorial, you will learn what gradient descent is, how gradient descent enables us to train neural networks, variations of gradient descent, including Stochastic Gradient Descent (SGD), and how SGD can be improved using momentum and Nesterov acceleration.
























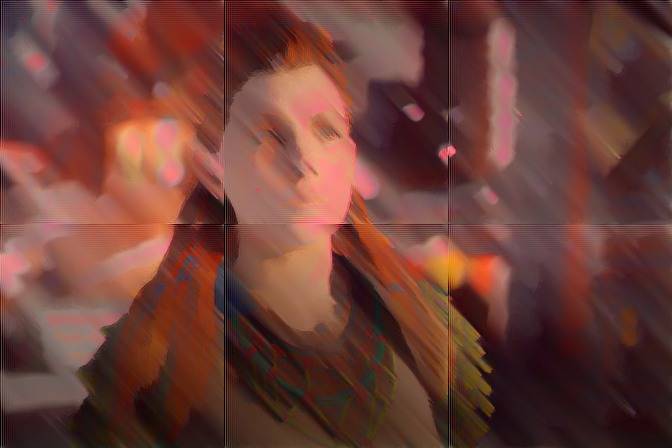
















































![[+]](https://www.chrisritchie.org/kilroy/archive/2021/11/back4blood_weps.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2015/07/warrior.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2021/11/veranda.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2019/01/viscera_cleanup_mop.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2021/12/dani_winery.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2015/02/far_cry_view_00.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2021/11/costumes.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2016/04/division_helo_00.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2021/12/teds_view.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2017/05/dying_light_stadium.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2021/12/b4b_abomination_cavern.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2016/08/witches_lair.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2021/12/fc6_trejos_tacos.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2015/11/deezer.jpg){kind=link}
{kind=link}
{kind=link}