Last time I got
Stable Diffusion's Hello World going (with some video card and Python IDE side quests).
This time: prompts and parameters.
Strength
The strength parameter is a 0.0-1.0 value that
determines how creative the model will be with the image/text inputs. Here's the above photo of Vale with a descriptive prompt demonstrating strength values from 0.1-0.9:
As the machine learning model is given more freedom to redraw the scene,
Vale winds up back on a Yamaha, but on a bike that doesn't look quite right. Of course, this is just one run at each strength, another strength 0.9 run might give you something entirely different (but derived from the input image and generally following the prompt).
Prompts
Both txt2img and img2img use textual prompts to re/create images.
Lexica.art has a wealth of examples that help provide empirical guidance on prompt writing.
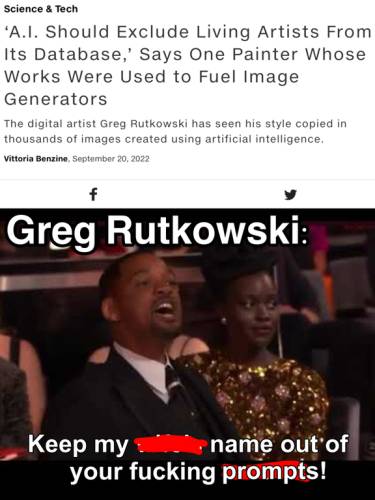
Artist
The
Andy's Blog post from last time mentioned that he saw
significantly better results when supplying one or more specific artists in the prompt. Either because his name yields good results or maybe because it's a meme,
a large chunk of Lexica uses Greg Rutkowski in its prompt. I'd never heard of Greg Rutkowski until trying out Stable Diffusion, but sure enough
he's quite prolific on Artstation which I think was one of Stable Diffusion's sources of tagged imagery.
Format
I've read a variety of things about
comma-separated tokens, natural language, and ordering by importance. The near-nondeterminism of deep learning makes it difficult to draw any conclusions on this.
The joy of AI painting using txt2img
With the basics in mind, I tried a bunch of different prompts, mostly producing 512x512 images that I've downscaled a little bit for this site. In the context of Style Transfer and Dall-e mini, the takeaway from the image dimensions is that
the output images are significantly larger than a 256x256 but still require additional work to be postcard size.
An abandoned factory
Starting simple...
ink illustration of an abandoned factory. retrofuturistic, photorealistic.
One looks like a traditional black and white photo, the other looks like architecturalish drawing. Both have signs of abandonment. One looks modern, the other looks brutalist.
A yellow starfighter
Next I juiced it up a bit, specifying subject color and a background. I pulled a random artist name from Lexica and whatever cgsociety is. And I went rectangular, probably along the wrong axis (as starfighters tend to be horizontal not that it matters in space).
python scripts/txt2img.py
--prompt "A highly detailed painting of a futuristic starfighter.
Yellow body, glowing cockpit. Concept art by ian mcque,
cgsociety. Sci-fi. Stars and nebulas can be seen in the
background."
--n_samples 8
--H 640 --W 320
Some of these
look like 70s sci-fi novel cover art. Cool.
CGI tools
Some of the prompts
specified a rendering platform (Unreal Engine, Maya, etc.), I think rendering and postprocessing tools are one of the tags in Artstation.
octane rendering of a colorful wormhole. soft lighting, cyberpunk,
hyper realistic.
It even has a watermark.
Vocabulary
Six months ago the PUBG crew
was wowed that Dall-e knew about battle royales. Stable diffusion does too:
Skaggy style
Likewise, SD knew about Claptrap and Borderlands art style. I used another random Artstation creator from Lexica.
unreal engine rendering of claptrap from borderlands in a field.
grainy, solarpunk, smooth render. in the style of andrei riabovitchev.
Looking at
Andrei's work the Borderlands elements seem to have dominated the style input.
Twist of the wrist
Trying some more subject/scene interplay:
source filmmaker cgi rendering of an aprilia motorcycle with blue accents
in a postapocalyptic waterfall. cyberpunk, photorealistic.
It doesn't look like a Prilly, but SD nailed the postapocalyptic waterfall. Other than some subtle details, the bike looks really good. Another:
cross-processed photograph of a ducati in a town square. dark, futuristic,
clean composition.
Go with what it knows
SD (as I understand it) is trained on a boatload of real images with human-applied tags. If you've seen the Silicon Valley where Erlich enlists Big Head's college class to tag datasets for him, it's unrewarding work.
The neat thing about using Artstation (and others?) as a datasource is that the imagery there is tagged and ready for deep learning consumption.
So while Stable Diffusion might have to guess what a banana with a goatee looks like,
it can recreate isomorphic things with considerably more certainty. Likewise, if every instance of something looks very different ("draw me a vehicle") an SD prompt might yield a mashup of those things. But a more refined command like "draw me a Jaguar XJ220" will give it more specific criteria to generate from.
Further, let's consider a Ferrari, here's some mild hyperbole that probably dicatates how well a deep learning algorithm can understand one:
- There are lots of photos/drawings of them.
- Exotic car photos usually have just a few canonical angles.
- They come in like three colors.
- They aren't typically modified.
- The company has a signature style that is visible in most of their vehicles of a given generation.
So 'car' is bad, 'Bugatti' is good, 'Toyota' is okay. Your mileage may vary.
Monochrome photograph of a Lamborghini parked in the rain. Contrasty.
Highly detailed but smooth.
The joy of AI repainting using img2img
Switching gears (lmao) to the other side of Stable Diffusion,
prompts are just as important to img2img.
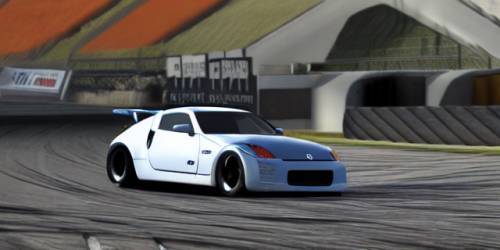
Drifter
I grabbed a photo from the archive and asked Stable Diffusion to recreate it in something contextually-similar: Gran Turismo.
Writing a specific prompt (not sure if this is good or bad) was a lot easier since I just had to describe what's in the image.
cgi rendering in the gran turismo engine. nissan 350z drifter on a
racetrack. tires smoking, front wheels at opposite lock. stickers
cover the scuffed bodywork.
It's definitely Gran Turismo-like. That last car's spoiler seems to be glitching though.
Archangel
Since Stable Diffusion knows about Borderlands, I thought I'd try a screencap of everyone's favorite Turian police sniper? Just to throw it a curveball, I asked for a plate of nachos.
detailed 35mm photograph of garrus vakarian from mass effect. standing in
front of colorful artwork, holding a plate of nachos.
Photo -> cgi worked pretty well with the 350Z,
cgi -> photo wasn't so good. 33% nacho rate though. Not bad.
AI green screen
Back to contextually-similar, recognizable things, I asked Stable Diffusion to reimagine a paintball photo as a highly specific war photograph.
world war 1 photograph of troops crossing no man's land wearing gas masks.
smoke billows in the background. mortars explode nearby.
Faces and hands
Things frequently go awry when Stable Diffusion tries to do faces and hands, with the exception of passport-headshot-style photos that are probably well-represented in its dataset. Generated words resemble text but aren't coherent (see above where Valentino Rossi is riding an "OIHNJOD").
- Photo -> CGI: good
- CGI -> photo: meh
- Photo -> painting: ???
I wanted to see how a photo would look as a painting.
digital painting of a surfer sitting in the lineup. wearing a shark tooth
necklace because he's a kook. very detailed, art by greg rutkowski.
pastel colors. green water, blue sky.
Stable Diffusion was pretty shy about redrawing the subject's face. Other things turned out rather incoherent. I said Greg Rutkowski, not
GWB.
Iterating img2img
You guessed it,
img2img outputs can be pruned and fed back into the algo with an identical or modified prompt. Here are some (not the same prompt):
A generative pipeline
Now for an end-to-end run:
txt2img followed by numerous passes of img2img with refined prompts.
cgi rendering of a gray lamborghini in the rain. contrasty, epic,
hyper realistic.
Draw me some lambos.
Oh yeah, AI can't draw wheels very well either.
Let's go with the low-angle one in the rain.
Time to fire up img2img. Monochrome is nice and all, but these cars deserve bright colors so let's change the prompt a little:
Colorful cgi rendering of a bright green Lamborghini in the rain.
Contrasty. Highly detailed but smooth.
and one of the photos looks like a fireplace. Hmmm. Maybe the one with the neat reflection. Let's keep the bright green and instead put the lambo in its natural environment: the garage. Just kidding, the track.
Colorful cgi rendering of a bright green Lamborghini at Suzuka Raceway
in Japan. Contrasty. Highly detailed but smooth.
I see some grandstands and some safety barriers. The one with the short depth of field is pretty awesome though the car's front right wheel well may have disappeared. On the plus side, the car is truly bright green with some neat orange accents on the grill.
Let's try a different color scheme and maybe see if Stable Diffusion will put a muscle car air cleaner on a Lamborghini frunk (golf clubs need high-psi ventilation too).
Colorful cgi rendering of a Lamborghini in the orange and blue Gulf Oil
racing lervery. On track at Suzuka Raceway in Japan. Hood as a large
air cleaner hood scoop for its supercharger. Contrasty. Highly detailed
but smooth.
We're still pretty green and not at all looking like a GT40 lookalike.
Either 'Gulf Oil livery' isn't well represented in the dataset or we left the strength value too low in trying to preserve our work so far. Stable Diffusion did get creative with a Bugatti-ish redesign.
But what if the car was not on a racetrack in Japan but actually in the Swiss Alps? Well then it'd probably need to be a Lamborghini trophy truck.
Colorful cgi rendering of a lifted Lamborghini trophy truck racing in the
snow in the Swiss Alps. Contrasty. Highly detailed but smooth.
We got a couple of low-poly trophy trucks, a near-redraw, and a neat version on a snowy city street.
And this is how you can meander for hours without touching a single paintbrush or OpenGL API call.
Additional checkpoints
So this
nitrosocke guy created
a checkpoint (set of trained models) using Elden Ring images. I envision this as being like
transfer learning wherein final model is a generalized network (like a trained VGG-19) that is adapted to a specific dataset.
The Elden Ring style checkpoint is cool and worth dedicating some post to, but it's even more than that. The Elden Ring outputs are really good. That is,
the images are more distinct, coherent, and stylistically-accurate than stuff generated by the base model. Of course it would make sense that a specialized network is better at its job.
There's one caveat that I'll mention after some Elden Ring txt2img:
Caveat:
Elden Ring characters often armor covering their face and hands so it sidesteps SD's weakness.
Trading Torrent out for a motorcycle
(Torrent is your horse in Elden Ring.) Back to transfer learning, since the Elden Ring checkpoint derives from a more generalized base model, it knows what a motorcycle is.
|
|
Source. Kind of like the Thomas mod for Skyrim. |
Elden Ring-Mass Effect crossover
Armor makes the jump pretty easily from sci-fi to fantasy.
Caelid Highway
There were some interesting takes on the Z-car photo, including one that had Gran Turismo in the prompt.
Paintball with scythes
The paintball image was easy for SD to redraw in Elden Ring style.
Code
The canned examples are pretty good for one-off runs, but consistency isn't great.
A successful generative process requires a lot of runs and a lot of variation. The Stable Diffusion sample scripts are small enough to modify easily, but do require some work (e.g. nested withs that have you starting lines at column 60). I made the following mods:
- Parameterized repeat runs (not using batching) as well as iterating over a full directory of inputs.
- Parameter randomization (strength, ddim, etc.).
- A prompt generator and mutator, e.g. "photo/photograph/35mm photograph of red/green/blue lambo/ferrari/citroen on a street/track/dirt road by greg rutkowski/greg rutkowski/greg rutkowski".
Some posts from this site with similar content.
(and some select mainstream web). I haven't personally looked at them or checked them for quality, decency, or sanity. None of these links are promoted, sponsored, or affiliated with this site. For more information, see
.































































































































































![[+]](https://www.chrisritchie.org/kilroy/archive/2022/10/oktoberfest.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2015/07/warrior.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2022/05/carousel_ride.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2019/01/viscera_cleanup_mop.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2022/09/across_the_obelisk_martyrdom.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2015/02/far_cry_view_00.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2022/05/elden_ring_jarburg.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2017/05/dying_light_stadium.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2022/05/elden_ring_flamethrower.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2016/04/division_helo_00.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2022/06/leopard.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2015/11/deezer.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2022/05/elden_ring_erdtree_avatar.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2020/09/da_bears.jpg){kind=link}
{kind=link}